Computer Networking Lecture Notes
25 April 2013 • Peer-to-Peer Routing
Outline
- What is peer-to-peer routing?
- Routing in
- Unstructured networks.
- Structured networks.
- Hybrid networks.
Peer-to-Peer Routing
- Peer-to-peer network routing is predominantly anycast routing.
- I want an item like this; get me one.
- Or find me a node that has one.
- A routing request is a query for a match to some specification.
Network Architectures
- Peer-to-peer network architectures can be divided into
- Unstructured: unconstrained links and undifferentiated nodes.
- Structured: constrained links and undifferentiated nodes.
- Hybrid: constrained links and differentiated nodes.
- Network organization increases down the list.
Unstructured Network Routing
- An unstructured peer-to-peer network admits arbitrary graphs.
- The principle benefits to unstructured networks are
- Dead simple routing protocols.
- Tolerates dynamic behavior.
- The principle costs are
- Inefficient and inconsistent results.
- Unpredictable search behavior.
Breadth-First Search
- Breadth-first search (BFS) is flooding.
- There’s no central pending-node queue.
- True concurrent execution.
- Per-node housekeeping to
- Suppress redundant messages.
- Keep a back-trail for results.
- Hop counts and filtering keep down costs.
BFS Example
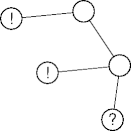
BFS Analysis
- BFS is easy to implement.
- Modulo the per-node record-keeping.
- BFS results may not demonstrate useful properties.
- Non-minimal path lengths.
- BFS is hard to control.
- Exponentially increasing useless searches.
- Multiple matches impinging on the querying node.
Depth-First Search
- Depth-first search (DFS).
- Per-node housekeeping to
- Suppress redundant visits.
- Keep a back-trail for results.
- Hop counts limit search depth from querying node.
- The infinite-graph problem doesn’t apply.
DFS Analysis
- DFS is easy to implement.
- Modulo the per-node record-keeping.
- Search results demonstrate the usual DFS properties.
- Undistinguished search characteristics.
- Next-hop choices mildly influential.
- Sub-optimal search results.
- Undistinguished search characteristics.
- DFS is easy to control.
- A meaningful next-hop choice.
- Termination is automatic and complete.
Routing Heuristics
- A heuristic is a guideline or rule of thumb that may suggest an
improvement.
- Not guaranteed to be effective.
- Select a few appropriate heuristics to apply to an algorithm.
- Often other heuristics are needed to undo earlier heuristics’ side-effects.
Iterative Deepening
- Iterative deepening is a standard AI search heuristic.
- Use the hop count to gradually expand repeated searches.
- Transit-node bookkeeping avoids redundant searches on successive iterations.
- Timing-out the previous iteration starts the next iteration.
- Up to some maximum hop count.
Directed Choice
- Breath- and depth-first searches make random or unconstrained choices.
- Send to all neighbors, or pick some neighbor.
- Assume some choices are better than others.
- Some neighbors lead to a solution, others don’t.
- Directed choice tries to make better choices.
- Heuristics for better choices.
Results-Based Heuristics
- Better choices are those that lead to success in the past.
- Some nodes have more items, and some neighbors lead to better nodes.
- Charge each neighbor with successes and failures.
- There’s many success measures.
- Choose high-success neighbors over low-success ones.
Query-Based Heuristics
- Successful results depend on the query.
- Nodes successful with movies may not be successful with technical reports.
- Keep track of which queries each neighbor is notably successful at.
- Match each query with the more successful neighbors for that query.
- More heuristics for determining query similarity.
Random-Choice Heuristics
- Biasing heuristics don’t react well to changes.
- New or improved nodes aren’t successful and won’t be selected.
- Random-choice heuristics combat bias by occasionally choosing
at random.
- Second-chance mercy.
- New nodes may be marked for a better than random inclusion rate.
Structured Network Routing
- A structured peer-to-peer network imposes some organization on the
network links.
- The nodes are largely interchangeable outside the routing protocol.
- The principle benefits are
- More consistent and complete results.
- More resource-efficient query mechanisms.
- The principle costs are more complexity and greater overhead.
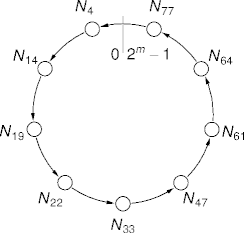
Chord
- Nodes and data are hashed into large (16-byte, for example) numbers.
- The collision probability is vanishingly small.
- Hash values are reduced modulo 2m, m a system parameter.
- Each node i references its successor, the node with the
smallest index at least i.
- With modulo wrap.
- The result is a Chord ring of nodes.
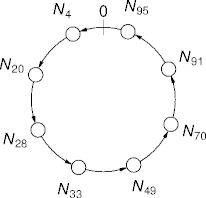
Chord Ring
Data Storage
- Each item is hashed and reduced modulo 2m.
- Item k is stored a node i for the smallest i at least k.
- A node contains all items falling between it and its predecessor.
|
|
|
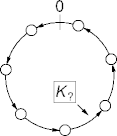
Basic Look-Up
- The query item is hashed and reduced modulo 2m.
- The search starts at the lowest indexed node and follows the successor chain.
- The search ends when
- the item is found or
- the node index exceeds the query key.
|
|
|
Scalable Chord Search
- Basic Chord look-up is linear, which isn’t scalable.
- A sub-linear search must make bigger jumps.
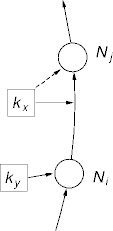
- Each node has an m-element finger table.
- The ith element of node j’s the finger table is a
reference to node k.
- K is the smallest node index at least (j + 2i) modulo 2m.
- The successor node’s at index 0.
Example
|
|
| ||||||||||||||||||||||||
Finger-Table Search
- To search for item k using a finger table:
- Find the largest predecessor node for k and continue the search there.
- If the successor is a predecessor for k, continue the search there.
- Search locally.
- Finger-table searches are logarithmic in the node count.
Node Management
- New nodes get inserted into the ring.
- Predecessor items are transferred from the successor node.
- The new node builds its finger table.
- The old nodes adjust their finger tables.
- Departing nodes off-load their items to successors, if possible.
- A periodic stability protocols adjusts the remaining finger tables.
Hybrid Networks
- Hybrid peer-to-peer networks impose structure by embracing
heterogeneity.
- Layers of more-capable and less-capable nodes.
- Each layer is a structured or unstructured peer-to-peer network.
- Higher layers do structure and routing, lower layers do storage.
- Examples include revised Gnutella and KaZaA.
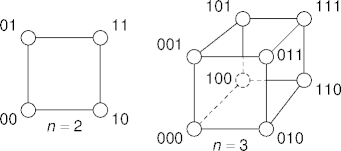
Hypercubes
- Consider 2n hosts, each uniquely identified by i, 0 ≤ i < 2n.
- Two nodes i and j are neighbors if i and j differ
in exactly one bit.
- With n = 3, nodes 7 (= 111) and 6 (= 110) are neighbors.
- Nodes 7 and 2 (= 010) are not.
- The resulting graph is an n-dimensional hypercube.
Examples
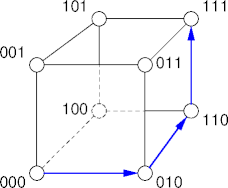
Hypercube Routing
- To send a message from node i to node j:
- Pick a bit that differs between i and j.
- Send the message along the associated neighbor link.
- Each bit in an address represents a dimension in the hypercube.
- Routing is linear in the number of address bits (logarithmic in the number of nodes).
Example
- To go from 000 to 111:
Edutella
- Edutella is an (apparently dead) two-layer hybrid peer-to-peer network.
- The upper layer contains superpeers in a hypercube network.
- Superpeers are responsible for node-item mapping (indexing) and routing.
- The lower layer contains common peers, each of which
- Connects to a super peer.
- Stores items.
Summary
- Peer-to-peer network routing is essentially anycast routing.
- Improving network structure increases search efficiency.
- At a cost of search overhead.
- Distributed hash tables provide a fairly simple distributed technique for structured-network routing.
References
- Routing in Peer-to-Peer Networks (Chapter 3) in Peer-to-Peer Computing by Quang Hieu Vu, Mihai Lupu and Beng Chin Ooi from Springer, 2010.
| This page last modified on 2011 October 9. |
|
