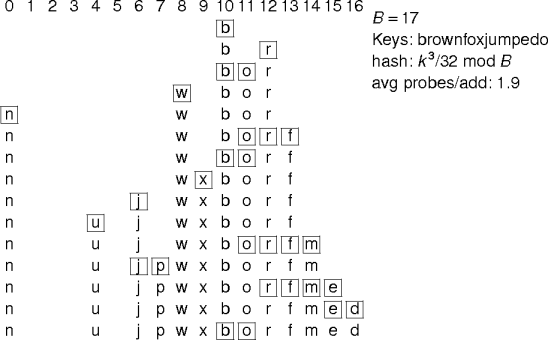
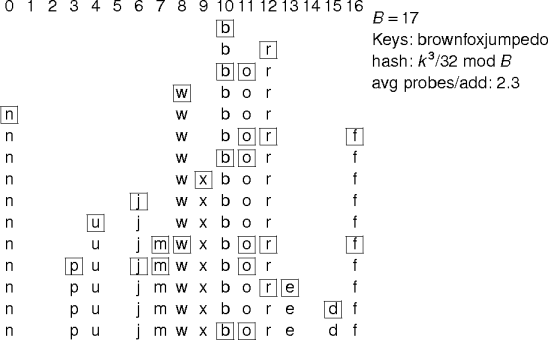
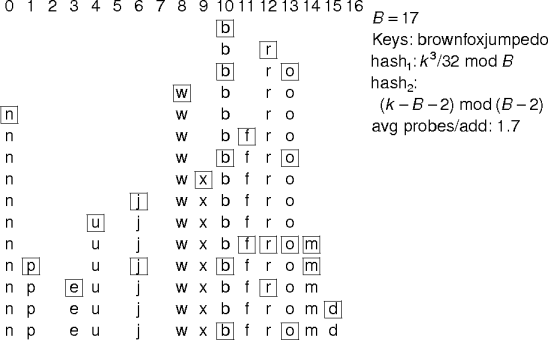
bool locate(key k, int & hi)
hi = hash(k)
u = 1 or i
2 or hash
2(k)
for i = 1 to B
if not occupied[hi] return false
if table[hi] == k return true
hi = (hi + u) mod B
hi = -1
return false
Public ADT Operations
void add(key k)
if not locate(k, hi)
if hi > -1
table[hi] = k
occupied[hi] = true
void remove(key k)
if locate(k, hi)
occupied[hi] = false
bool find(key k)
return locate(k, hi)
Implementation Details
- Two important implementation details are
- hash-table size (the value of B), and
- the hash functions.
Hash Function Issues
- Some important details for hash-function implementation include:
- How are they created?
- Who provides them?
- How good are they?
Hash Function Mechanics
- A hash function maps arbitrary data (the key) into a small range of
integers (the hash-table indexes).
- This can be divided into two steps:
- Reduce the key to an integer
- Reduce an integer to a hash-table index.
Keys To Integers
- The key-to-integer mapping is data dependent, but has the general form:
- Treat the key as a sequence of n-byte values for n
∈ { 1, 2, 4, 8 }.
- Use arithmetic to combine the values into a single value.
- There may be other techniques, such as use the key address.
Hash Functions
- Hash functions fall into one of three classes based on value
combination:
- Multiplication based, division based, or bit-twiddling based.
- There are also other techniques.
- Random-number generation is a closely-related area.
- For implementations and evaluations.
Hashing by Bit Twiddling
- Create
rp[], a random permutation of the 256 integers 0 to 255
(byte values).
- Given a sequence
v[] of n byte values, hash v into a
byte value h with
byte hash(byte v[], unsigned n)
byte h = rp[v[0]]
for i = 1 to n - 1
h = h xor rp[v[i]
return h
-
Combining several values
from
hash() produces multi-byte hash values.
Hashing by Division
- This is the typical hash function.
unsigned hash(unsigned k)
return k mod B
- Linear congruential generators are a variation.
unsigned hash(unsigned k)
return (M*k + a) mod B
- This is overkill, most likely.
Hashing by Multiplication
- Hashing by multiplication uses functions of the form
unsigned hash(unsigned k)
return floor(B*fraction(k*A))
Comments
- Random-permutation hashing is fast, reliable, simple, and general
purpose.
- Multiplication- or division-based hashing is less fast, less reliable,
less simple, and less general purpose than random-permutation hashing.
- Real arithmetic is expensive, and getting the parameters correct
is tricky.
Hash Function Sources
- Hash functions can be provided by the ADT, the ADT client or both.
- There may be other sources, such as a language run-time or a VM.
- The client knows about the data; the ADT knows about the hash table.
- Good hash functions needs to know about both.
ADT Hash Functions
Client Hash Functions
- These are mainly key-to-integer mappings.
Dual Hash Functions
- Not deciding is a good strategy: have the client and ADT each provide a
hash function.
- The final hash is hA(hC(k)).
- Each side can exploit its strengths without bothering the other side.
- The ADT can change its hash function without customer coordination.
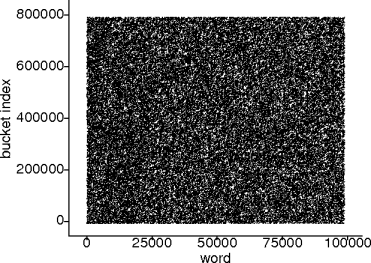
Evaluating Hash Functions
- A good hash function should generate indices that are uniformly and
randomly distributed over the buckets.
- There are mathematical (statistical) tests for evaluating randomness.
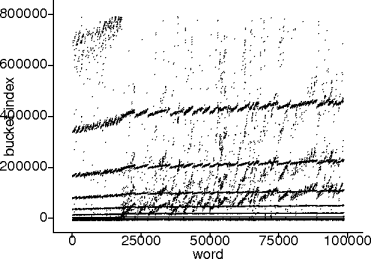
- A simpler alternative is to plot the hash function and look for
patterns.
- Patterns can indicate non-uniformity and non-randomness.
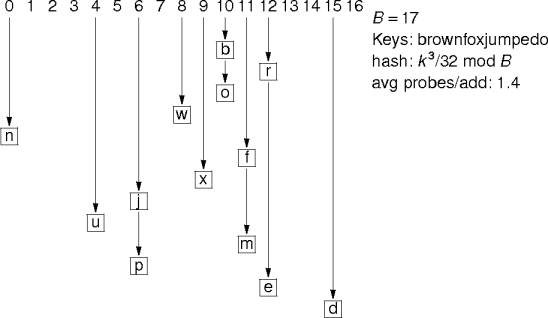
Example.
Example.
References
- Hashing, Section 6.4 in The Art of Computer Programming, Vol. 3:
Sorting and Searching by Donald Knuth, Addison-Wesley, 1973.
- Hash Tables by Pat Morin, Chapter 9 in Handbook of Data Structures
and Algorithms, edited by Dinesh Metha and Sartaj Sahni, Chapman &
Hall/CRC, 2005.
- Hashing, Chapter 9 in Algorithms by Robert Sedgewick,
Addison-Wesley, 1983.