Advanced Programming I Lecture Notes
6 April 2006 • Dynamic Hashing
Outline
Tries
Dynamic hashing.
Hash-Table Size
Hash-table size, and load factor, is crucial for good performance.
Unfortunately
Hash tables are based on static arrays.
There may be no useful bound on the number of possible keys.
For general utility hash tables have to overcome these problems.
The Current State
Open-address hash tables are not easily dynamic.
They require a complete rehash with a new hash function.
Chaining hash tables are dynamic, but at a performance cost.
And don'f forget that "dynamic" means growing and shrinking.
Dynamic Hash Tables
A
dynamic
(or
extensible
)
hash table
automatically reconfigures to maintain a given time-space trade-off.
The ADT client sets the parameters.
The client may explicitly request a resize.
Prerequisites
Databases use dynamic hash tables.
Minimizing disk I-O is important.
A higher tolerance for poorer hash performance.
Relatively small number of buckets (
B
) of relatively large size (
b
).
The STL unordered associated containers are dynamic hash tables.
Dynamic Components
The important parts of a dynamic-hashing scheme are
Addressing and hashing.
Storage
Collision and overflow handling.
Growing and shrinking.
Addressing
As the hash-table size changes, so does the hash function.
A new hash function forces a complete rehash of the table.
Expensive and doesn't amortize well.
The hashing scheme should adapt but manintain consistency with previous hashes.
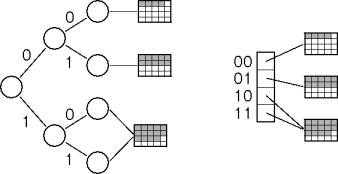
Tree-Based Addressing
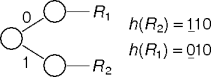
Consider storing records in a binary tree.
One record can be stored with no hash values at all.
Two records require discrimination on (at least) one bit.
The choice of left-most or right-most bits doesn't matter as long as it's used consistently.
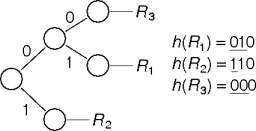
Tree-Based Collisions
When two records collide, use more hash-index bits.
Choose the smallest unique prefix (or suffix) of the original hash value.
This handles expansion and contraction.
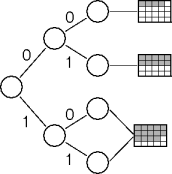
Big Buckets
Excessive expansion and contraction is inefficient.
And what about unbalanced trees?
Large-capacity buckets help smooth out these variations.
The bucket size
b
is a knob for tuning the time-space trade-off.
Storage
So much for addressing and hashing.
Addressing and hashing
.
Storage
Handling overflow.
Growing and shrinking.
What about storage?
Look to the trees.
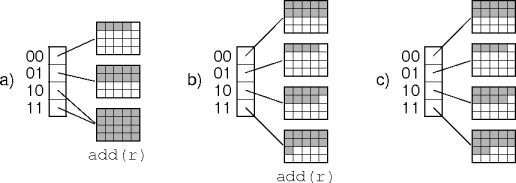
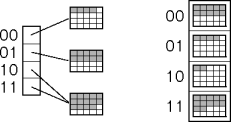
Directories
Collapse the tree into an array called the
directory
This is
directory-based dynamic hashing
.
No Directories
Directories add a level of indirection, reducing performance.
Hash directly to the appropriate bucket.
This is the
directoryless dynamic hashing
.
It trades space for time.
Lots of cheap storage may make this trade-off sensible.
Collisions And Overflow
Next up is handling collisions and overflows.
Addressing and hashing
.
Storage
Handling collisions and overflow.
Growing and shrinking.
There are several important trade-offs between collisions and reconfiguration.
It's not only the obvious "more collisions mean more reconfiguration."
Collisions
Given large bucket sizes, chaining is a good way to handle collisions.
Large bucket sizes may make non-linear chaining sensible too.
A tree or another hash table.
Eventually a bucket may fill, and on the next record add will
overflow
.
Hash tables need a scheme for dealing with overflow.
Overflow Buckets
Bucket overflow can be stored in
overflow buckets
.
Just like chaining.
Overflow-bucket size may be a hash-table parameter.
As may be the record redistribution from the full bucket.
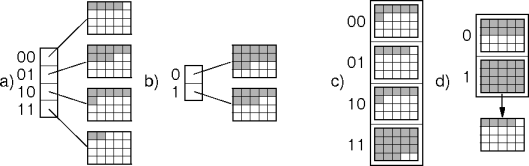
Directory Overflow
Overflow in a directory may be a special case.
An overflowing shared bucket can be split into two unshared buckets.
Growing and Shrinking
And finally, growing and shrinking.
Addressing and hashing
.
Storage
Handling collisions and overflow
.
Growing and shrinking.
Overflow handling can be used to delay expensive size changes.
But the load factor may get too extreme.
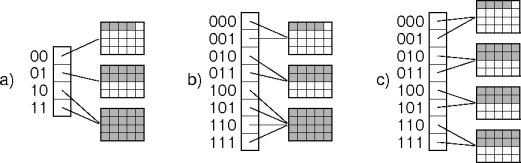
Directory Growth
Growing a directory hash is similar to the special case described previously.
Directory reconfiguration is relatively time and space efficient.
Directoryless Growth
Growing a directoryless hash is roughly the same as for a directory hash.
But it uses more time and space.
There's a more efficent
incremental scheme
.
But it's also less effective.
Shrinking
A per-bucket load factor of less than 0.5 suggests it's time to shrink.
If space is tight, contraction may be into overflow buckets.
References
Dynamic Hashing Schemes
by Richard Enbody and David Du,
Computing Surveys
, June 1988.
Hashing for Dynamic and Static Internal Tables
by Ted Lewis and Curtis Cook,
IEEE Computer
, October 1988.
This page last modified on 7 June 2006.
This work is covered by a
Creative Commons License
.