This problem started with some code I wrote last summer to strip font tags from web pages, particularly those generated by Microsoft and Apple web-page makers.
The problem is essentially a pattern matching problem: recognize font tags and
strip the tag text from them. Crafty programmers, when dealing with
pattern-matching problems, reach for regular expressions. Using the
regexp regular-expression library, it took about 20 minutes to write the
code and install it in a web filter; about three minutes to recognize that the
code was missing, in some cases, more than half the font tags in web pages; and
about an hour of diddling around with the code before remembering that the
problem probably lie with the piece-by-piece way in which web pages are
delivered to the filter.
After verifying that piece-by-piece delivery was causing the problem, the
problem was now to figure out how to deal with it. There seemed to be no
obvious way to get regexp to remember state from one piece to the next,
and other attempts to solve the problem with within regexp were notable
largely for their obscurity and complexity.
With regexp unsuitable, the font-tag regular expression had to be
implemented by hand, which involved implementing the finite-state machine
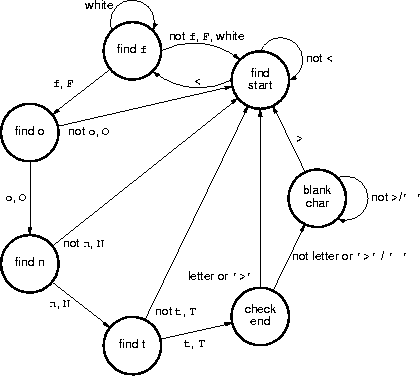
equivalent to the regular expression. Having spent two hours working with the
font-tag regular expression, the translation to finite-state machine came as
fast as it could be scribbled down on a piece of paper:
where a/b means "replace character a with character b".
While drawing the finite-state machine, I optimized it by combining the find-t and check-end states into one state. The new state was clumsy, with many arcs and complicated guards on each arc, and a quick check showed the optimized finite-state machine was wrong: it could recognize and strip a non-font tag. Rather than complicate the new state even more, I unoptimized the finite-state machine back to seven states. A quick inspection was enough to show the unoptimized finite-state machine stripped all, and only, font tags.
With the finite-state machine in hand, translation to code was simple. Seven states keep track of the search for font tags.
<fsm states>= (U->)
typedef enum {
find_start,
find_f,
find_o,
find_n,
find_t,
check_end,
blank_char
} states;
The transition from state to state is determined by the current state
(state) and the current character from the HTML text (html_text[i])
according to the diagram above.
<state switch statement>= (U->)
switch (state) {
case find_start:
if (html_text[i] == '<')
state = find_f;
break;
case find_f:
if (isspace(html_text[i]))
break;
else if (tolower(html_text[i]) == 'f')
state = find_o;
else
state = find_start;
break;
case find_o:
if (tolower(html_text[i]) == 'o')
state = find_n;
else
state = find_start;
break;
case find_n:
if (tolower(html_text[i]) == 'n')
state = find_t;
else
state = find_start;
break;
case find_t:
if (tolower(html_text[i]) == 't')
state = check_end;
else
state = find_start;
break;
case check_end:
if (isalnum(html_text[i]) || (html_text[i] == '>'))
state = find_start;
else {
html_text[i] = replacement_char;
state = blank_char;
}
break;
case blank_char:
if (html_text[i] == '>')
state = find_start;
else
html_text[i] = replacement_char;
break;
default:
std::cerr << "unhandled case in disable_font().\n";
exit(EXIT_FAILURE);
}
A quick and simple comparison between each case and the associated state in the diagram is enough to show that this code is a faithful translation of the finite-state machine.
The finite-state machine is animated by a linear scan of the input text.
<scan the input text>= (U->) for (unsigned i = 0; i < char_cnt; i++) <state switch statement>
Finally, start start the finite-state machine in the initial state and that's it: problem's solved.
<disable-font.cc>=
#include <cstring>
#include <iostream>
#include <stdlib.h>
#include <ctype.h>
<fsm states>
void disable_font(char * html_text, unsigned char_cnt) {
static states state = find_start;
const char replacement_char = ' ';
<scan the input text>
}
disable-font.cc>: D1
This page last modified on 5 February 2001.