Computer Networking Lecture Notes
2014 October 8 • Network Routing
Outline
- Networks and graphs.
- Workhorses: distance-vector and link-state routing.
- Hierarchy
- Broadcast and multicast routing.
- Oddballs: anycast, mobile-host, and ad-hoc routing.
Where We Are
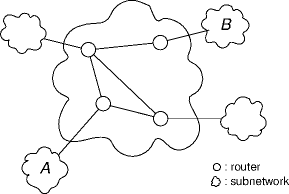
What’s the Problem?
- Throw a PDU in one side of the network, have it come out on the other
side.
- At the PDU’s destination.
- For the network PDU sources and destinations are other networks.
- The smaller subnetworks.
- Networks don’t address processes or hosts.
- PDUs should move through the network quickly, efficiently, …
What’s the Solution?
- Network routing moves PDUs from edge to edge through the network.
- Via an interconnected set of routers.
- A router is a special-purpose host.
- The interconnections between routers are network links.
- Collectively known as “the network.”
Network Routers
- A network router (or router or layer 3 switch)
is a special-purpose host.
- Multiple network interfaces.
- Incomplete protocol stack (up to the network layer).
- Optimized to perform network routing.
Oh, Routing’s Easy
- Forward arriving PDU on all other links.

- Flood routing (or flooding).
- Simple, never fails, no routing tables.
- May run forever, exponential growth, no optimal properties.
Flooding
- Despite exponential growth, flooding is important.
- No preparation, always available, fault-tolerant.
- Flooding frequently appears in initialization.
- All over in peer-to-peer and sensor networks.
- But exponential costs can’t be paid for.
- How can flooding be tamed?
Dampening
- Drop packets after x hops.
- x is receiver distance or network diameter.
- Only forward packets once.
- Tag packets with network-unique ids.
- Routers keep forwarded-packet lists.
- Not close to being scalable.
- Acyclic network topologies naturally dampen floods.
- Bus or tree networks.
The Routing Problem
- Move PDUs from subnet to subnet through the network.
- Flooding’s too expensive for general use.
- Is there a better way?
- Find good source-destination paths through the network.
- When a PDU arrives, send it along the proper path.
- These two tasks are routing and forwarding.
Finding Good Paths
- Finding good paths has known solutions:
- representing the network as a graph
- run a shortest-path algorithm on the graph
- use the resulting paths in forwarding.
- This approach is question-begging.
- Building the graph, running shortest path, distributing the result,…
- But other routing algorithms should behave like this.
Distance-Vector Routing
- Distribute shortest path to each router.
- Each router maintains a list (a table, a vector) of triples
(destination, out-link, cost)
- Periodically routers exchange their lists with adjacent routers (neighbors).
- Each router updates its list using neighbor lists.
- Iterative shortest-path.
Distance-Vector Updating
- Neighbor n sends (d, *, cd) to r.
- If (d, *, *) is not in r’s list,
add (d, out-linkn, cn + cd)
- If (d, old, cd) is in r’s list
- If r.cn + n.cd < r.cd or
r.old = r.oln, replace
(d, old, cd) with (d, oln, r.cn + n.cd)
- Otherwise do nothing.
- If r.cn + n.cd < r.cd or
r.old = r.oln, replace
Convergence
- Routers converge when they all agree on shortest paths.
- Distance-vector routing converges
- rapidly on good news,
- slowly (hop-by-hop) on bad news.
- This is the count-to-infinity problem.
- Which renders distance-vector routine less practical.
Network Topology
- Distance-vector routing fails because it is path-independent.
- Routers update tables solely on cost.
- Make routers path-aware by learning the network graph.
- Each router runs a shortest-path algorithm.
- Distribute network topology (with costs), not routing information.
- This is link-state routing.
Link-State Routing
- Periodically do
- Discover neighbor addresses.
- Determine costs to neighbor.
- Broadcast neighbor information to routers.
- Add received neighbor information to the graph.
- Compute shortest paths.
- This is what the Internet currently does.
Link-State Distribution
- A Link-state packet contains
- a list of (neighbor, cost) pairs
- a 32-bit sequence number to control flooding
- a time-to-live value for corruption and crashes.
- Other refinements make the algorithm more robust.
- Out-bound buffering to suppress redundancy.
In Practice
- Link-state routing has two main variants:
- Intermediate System-Intermediate System (IS-IS).
- From DECnet to ISO OSI to IP.
- Open Shortest-Path First (OSPF)
- From the IETF.
- Intermediate System-Intermediate System (IS-IS).
- They are, essentially, the same.
- IS-IS has an advantage in multi-protocol environments.
Hierarchy
- Distance-vector and link-state routing don’t scale with size.
- Larger networks use more resources for all routers.
- Deal with size using hierarchy.
- The big network is partitioned into smaller regions (or areas, or zones, or …).
- The regions are linked together by a new parent area (or zones, or segments, or …).
- Repeat until satisfied.
Hierarchy Examples
- The U.S. phone system (268 million phones in 2003) is a five-layer
hierarchy.
- The lowest level, the central office, is about 1000 phones.
- The Internet is an n-layer domain hierarchy.
- Structure determined by authorities in each domain.
- The Lightweight Directory Access Protocol (LDAP, rfc 4511) is an n-layer addressing hierarchy.
Hierarchical Routing
- Doesn’t something have to know about everything at some point?
- Hierarchical routing:
- If level i doesn’t know address a, move it up to level i + 1.
- The address doesn’t exist if the root level doesn’t know about it.
- So does the root level know everything?
Broadcast Routing
- Broadcast routing delivers a packet to all destinations.
- Flooding is address-less broadcasting.
- Point-to-point simulated broadcast is simple and inefficient.
- Multidestination routing is a more efficient point-to-point
simulation.
- Each packet contains multiple destination addresses.
- Routers duplicate packets as needed.
Flooding Revisited
- A flooding packet p arrives at router r on link k.
- Sender s must think k is the best way to get to r.
- R concludes k is the best way to get to s.
- If p arrives on any other link, it’s a duplicate.
- This is reverse path forwarding.
Hierarchical Flooding
- If level i doesn’t know address a, flood level i - 1.
- Associate the responding level i - 1 grouping with a.
- Otherwise, forward a to level i + 1.
- And remember that too.
- Hierarchical routers learn routing table entries while routing.
- With some inefficiency and cost.
Multicast Routing
- Multicast routing generalizes multidestination routing.
- Each multicast address represents an address set of receivers.
- Address management is separated from multidestination routing.
- The routing algorithm moves from sink trees to spanning trees.
Multicast Trees
- A broadcast creates a spanning tree to all receivers.
- Routers not delivering useful multicast packets can be pruned.
- The result is a multicast spanning tree.
- Pruning algorithm can follow unicast routing algorithms
- Multicast OSPF (MOSPF) - topology based.
- Distance-Vector Multicast Routing Protocol (DVMRP) - reverse path forwarding.
Anycast Routing
- Here’s a routing problem: send this file to a color PostScript printer.
- Or maybe the nearest, cheapest color PostScript printer.
- This is anycast routing.
- Anycast routing algorithms redefine costs in unicast routing
algorithms.
- Each feature provided by a node adds 1 to its cost.
Mobile-Host Routing
- Mobility and IP don’t work well together.
- IP addresses interfaces, which are presumed stable.
- Remember network + host IP addressing.
- The basic idea is to define a
- Home location to represent the to-address.
- A remote proxy as current host.
- Connect home and proxy.
Ad-Hoc Network Routing
- Now imagine nothing is stationary, routers included.
- This does not necessarily imply wireless.
- Two possible approaches:
- Every node becomes a (part-of a) router.
- Some nodes are chosen to be routers.
- We will consider these in more detail in sensor and peer-to-peer networking.
Summary
- Networks can be represented as graphs, and routes are graph paths.
- Routing algorithms build and maintain graph models of the network.
- The workhorse Internet routing algorithm is the link-state algorithm
OSPF.
- Although other algorithms are used as appropriate.
- Hierarchy is an important technique for scalable routing.
| This page last modified on 2014 October 8. |
|
