Computer Algorithms II Lecture Notes
27 November 2007 • Balancing Trees
Outline
Tree Shape
Rebalancing Trees
AVL Trees
Red-Black Trees
Caching
Splay Trees
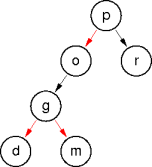
A Question
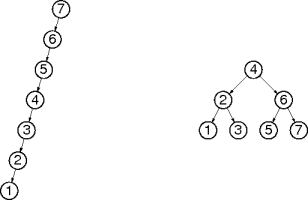
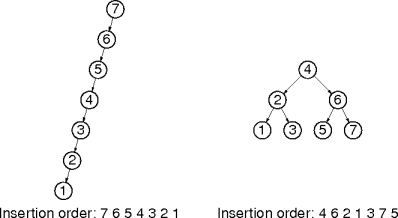
Here are two binary search trees containing the same data.
Why are they different?
Data Insertion Order
Data-insertion order determines a tree's shape.
Tree shape influences tree operation performance.
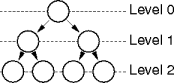
Tree Levels
A node
n
is at
level
i
in a tree
T
if
n
is
i
edges away from the root.
The
ith
level of
T
is the nonempty set of all nodes at level
i
in
T
.
A node's
depth
d
is the node's level.
A tree's
height
h
is the largest level in the tree.
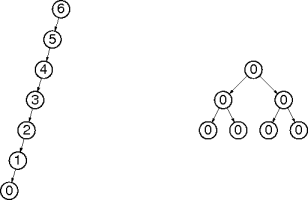
Tree Shape
Tree operations have good performance when each decision throws away half the data.
This occurs when each subtree has half the data.
This property is captured by the notion of
balance
.
A tree is
balanced
if any two sibling subtrees
differ in height by at most 1
.
Examples
Representing Balance
For efficiency, each node maintains balance information for its subtree.
Balance information can be an integer down to no overhead (pointer encoding).
Each node stores the difference in its children's heights.
The sign indicates the larger subtree, the magnitude by how much.
Getting Balanced Trees
Several techniques produce balanced trees:
Shuffle the data before inserting it.
May not be practical or always applicable.
Ocassionally reconstruct a balanced tree.
Effective but possibly expensive.
Rebalance the tree after every operation.
Effective, moderately expensive, complicates operations.
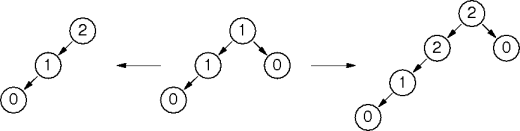
Tree Balance
A balanced tree can be unbalanced by at most 1.
Shifting a node from one child to the other restores balance.
For some interpretation of “shifting”.
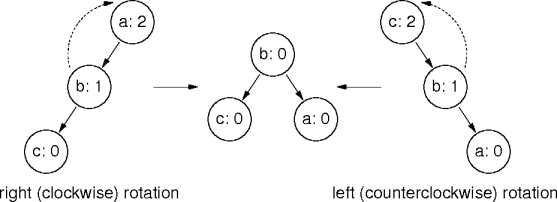
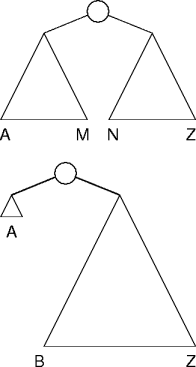
Node Rotations
A
node rotation
lifts nodes up in the tree.
The rotation is the basic rebalancing operation
Tree Rebalancing
An insertion or deletion can unbalance the whole tree.
But only by one.
A rotation restores balance locally.
Walk back to the root, rotating into balance as needed.
This does logarithmic work per insertion or deletion.
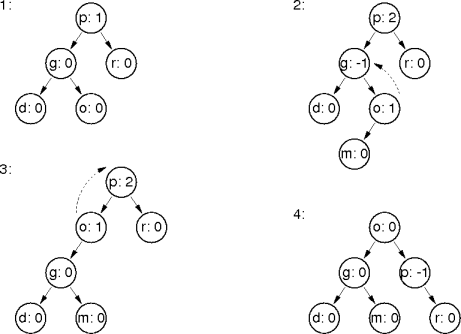
Example Rebalancing
AVL Trees
The
AVL tree
is a binary search tree that's always in balance.
Developed in 1962 by Georgii Adelson-Velsky and Yevheniy Landis.
Each unbalancing insertion or deletion restores balance as part of its operation.
Not so popular these days.
More efficient and simpler alternatives are available.
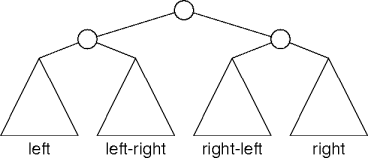
AVL Rotations
AVL trees require four kinds of rotations.
The left-right and right-left rotations are double rotations.
They each have three cases.
AVL Balance
At most one (possibly double) rotation is enough to restore balance after an insertion.
Restoring balance after a deletion may require
O
(log
n
) rotations.
Search is always
O
(log
n
).
Almost-Balanced Trees
Constantly maintaining balance can be expensive.
Particularly if insertions and deletions outnumber searches.
Let the tree drift out of balance, and fix it up when it gets too out-of-balance.
Most operations are now cheaper.
Some operations are more expensive.
However, they're still
O
(log
n
).
Red-Black Trees
The
red-black tree
is an example of an almost-balanced tree.
Developed in 1972 by Rudolf Bayer.
A red-black tree is a binary search tree.
The
edges of the tree
are either red or black.
Red-black trees implement the STL sorted-associative containers.
The Red-Black Property
The
red-black property
generalizes
height.
Every path from root to leaf has the same number of black edges.
All paths are roughly in balance.
No path contains two consecutive red edges.
Paths do not drift too far out of balance.
"Too far" in this case means "at most ×2".
Example Red-Black Tree
Inserting into the left sub-tree requires rotations.
There are (potentially) two rotation-free insertions into the right subtree.
Maintaining Almost Balance
Insertions and deletions must maintain the red-black propery.
Using tree rotations and edge color-flipping.
The no consecutive red-edges property requires keeping track of more information.
Parents and grandparents.
Rotations cover larger portions of the tree.
There are more cases to implement.
Abandoning Balance
Data access is frequently unbalanced.
A book chapter on Italy contains a lot of “Rome” but little of “Paris”.
Seniors register for classes two days before juniors do.
Balance is unhelpful when data accesses are skewed.
Improve performance by recognizing and exploiting unbalanced access.
Unbalanced Trees
With unknown (or random) access patterns, balance is best.
With biased access patterns, unbalance the tree to match the bias.
But what if the access bias changes?
Caching
Caching
exploits unbalanced access.
A
cache
is a high-performance database.
Both search and access are fast.
Caches are also usually expensive and small.
Skewed accesses should be satisfied out of the cache.
Other accesses go to the main data set (a
cache miss
).
A List Cache
Searching a linked list has linear cost.
Ordering doesn't change that.
When an element is accessed, move it to the list head.
The list head is the cache.
Skewed accesses are satisfied within a few elements.
The cache adjusts to changes in access skew.
Caching Tree Accesses
Tree accesses can be cached by moving data to the root.
But unordered trees are just expensive lists.
Worst case behavior rises from
O
(log
n
) to
O
(
n
).
Extra space and complexity overhead.
Splay Trees
A
splay tree
is a caching binary search tree.
Developed by Daniel Sleator and Robert Tarjan in 1985.
Splay-tree operations provide amortized
O
(log
n
) operations.
Maintaining search-tree order has its price.
Splaying
Move-to-the-root is done by splaying operations.
Each operation also appliess splays to the element accessed.
A
splaying operation
is a sequence of rotations.
Each rotation moves a node up the tree.
Summary
Ordinary binary-search tree performance is data dependent.
Self balancing trees guarantee performance.
At an implementation-complexity cost.
Sometimes “almost” is good enough.
Particularly if it's much less expensive.
The caching heuristic is valuable; recognize and exploit it.
Credits
Under this tree, I took a nap
by
Marcus Derencius
,
AT CC licensed
.
This page last modified on 26 November 2007.
This work's
CC license
.