This page presents a solution to the first programming
assignment, which involves writing a process manager.
The operating system is made up of managers for the disk, the CPU, User Space,
and the interrupts:
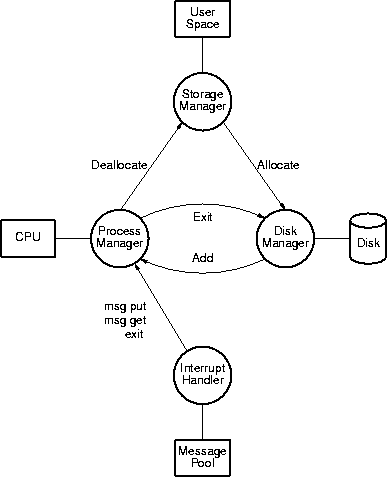
Circles represent operating-system manager software; non circles represent
resources, either hardware (such as the disk) or software (messages). Arrows
between managers indicate interactions via subroutine calls; the caller is
pointing and the called is being pointed at. The labels associated with each
arrow gives the system event that triggers the subroutine call. For example
the arrow labeled "Exit" from the Process Manager to the Disk Manager
indicates that the Process Manager makes a subroutine call to the Disk Manager
(via a routine provided by the Disk Manager) whenever a process exits the
system.
The disk manager is responsible for loading programs. The interrupt handler is
responsible for initializing the other managers on system boot-up; these
interactions are not shown in the diagram.
Handle a system-call interrupt.
<interrupt handlers>= (U->) [D->]
static void syscall_ih(void) {
word w;
fetch_mem(0, w, syscall_ih);
switch (w) {
case system_call::put_msg: {
word tag, data;
fetch_mem(1, tag, syscall_ih);
fetch_mem(2, data, syscall_ih);
store_mem(0, status::ok, syscall_ih);
msg_pool::put(tag, data);
break;
}
case system_call::get_msg: {
word tag;
fetch_mem(1, tag, syscall_ih);
store_mem(0, status::ok, syscall_ih);
msg_pool::get(tag);
break;
}
case system_call::exit:
process::exit();
break;
default:
store_mem(0, status::bad_system_call, syscall_ih);
}
}
Defines syscall_ih (links are to index).
On boot-up, install the system-call interrupt handler and initialize the
process, storage, and disk resource managers. The disk resource manager starts
reading in the programs.
<interrupt handlers>+= (U->) [<-D]
void reboot_ih(void) {
mass.memory->set_ihandler(system_call_i, syscall_ih);
process::init();
storage::init(usr_base, usr_size/disk_block_size);
disk::init();
}
Defines reboot_ih (links are to index).
<interrupts.cc>=
#include "os.h"
#include "disk.h"
#include "storage.h"
#include "process.h"
#include "mpool.h"
unsigned read_clock(void) {
word c;
fetch_mem(clock_register, c, read_clock);
return c;
}
<interrupt handlers>
Defines interrupts.cc (links are to index).
A process is identified by a unsigned integer unique among all existent
processes.
<process interface declarations>= (U->) [D->]
typedef unsigned id;
Defines process::id (links are to index).
process::add() creates a new process from the program loaded into User
Space at the location given by sc. process::exit() deletes the running process,
freeing up all resources held by the process.
<process interface declarations>+= (U->) [<-D->]
void add(const storage::chunk & sc);
void exit(void);
process::init() initializes the process manager; process::done()
returns true if and only if the idle process is the only remaining process;
process::halt() halts the simulation.
<process interface declarations>+= (U->) [<-D->]
void init(void);
bool done(void);
void halt(void);
process::block() suspends the currently running process and schedules a
replacement, returning the newly blocked process's id. process::ready()
makes the blocked process identified by pid ready to run.
<process interface declarations>+= (U->) [<-D->]
id block(void);
void ready(id pid);
Some of the other managers need to be able to store values into the saved
register context for a particular process; process::put_register() makes
that possible.
<process interface declarations>+= (U->) [<-D]
void put_register(id pid, unsigned r, word v);
A process may be blocked waiting for a non-cpu resource, ready to use the cpu,
or executing in the cpu.
<process data structures>= (U->) [D->]
enum process_status {
proc_blocked,
proc_ready,
proc_executing
};
Defines process_status (links are to index).
A process-table entry contains all the information needed to manage a process,
including the process's id, its status, its saved register context, and
information about the User Space storage allocated to it.
The process table entry also contains code to allocate process ids and save and
restore process register contexts.
<process data structures>+= (U->) [<-D->]
struct process_table_entry {
static process::id next_id;
process_table_entry() : id(next_id++) { }
const process::id id;
process_status status;
word registers[next_register];
storage::chunk sc;
void save_state(void) {
for (address a = 0; a < next_register; a++)
fetch_mem(a, registers[a], save_state);
}
void restore_state(void) const {
for (address a = 0; a < next_register; a++)
store_mem(a, registers[a], restore_state);
}
};
unsigned process_table_entry::next_id = 0;
Defines process_table_entry, restore_state, save_state (links are to index).
Process-table entries are stored in a list, with special iterators indicating
the entries for the currently running process and the idle process (which may,
on occasion, be the same process).
<process data structures>+= (U->) [<-D]
typedef std::list<process_table_entry> process_table;
typedef process_table::iterator ptab_iter;
static process_table ptab;
static ptab_iter running_process;
static ptab_iter idle_process;
Defines idle_process, process_table, ptab, ptab_iter, running_process (links are to index).
Loading a process into the cpu involves changing the process's state to
executing and restoring the saved register state.
<process procedure definitions>= (U->) [D->]
static void load_cpu(ptab_iter & pi) {
pi->status = proc_executing;
pi->restore_state();
running_process = pi;
debugp(dbp_execute, "At time %d, process %d runs.\n",
read_clock(), running_process->id);
}
Defines load_cpu (links are to index).
Return an iterator to the process-table entry with id equal to pid; die
with an error if there's no such entry.
<process procedure definitions>+= (U->) [<-D->]
static bool find_pid(const process_table_entry pte, process::id pid) {
return pte.id == pid;
}
ptab_iter find_proc(process::id pid) {
const ptab_iter & e = ptab.end();
ptab_iter i = find_if(ptab.begin(), e, bind2nd(ptr_fun(find_pid), pid));
if (i == e)
oops("Can't find the process with process-id %d", pid);
return i;
}
Defines find_proc (links are to index).
A couple of helper predicates to find process-table entries of ready or running
processes.
<process procedure definitions>+= (U->) [<-D->]
static bool readyp(process_table_entry & pte) {
return pte.status == proc_ready;
}
static bool runningp(process_table_entry & pte) {
return pte.status == proc_executing;
}
Defines readyp, runningp (links are to index).
If the idle process is running, check the process table for a ready process and
run it if found. If no process is running (because the running process exited)
find a ready process and run it (this should always be possible because the
idle process is always around and always ready).
If, after all this, the idle process is still running, then it's time to halt
the system if both the process and disk managers are done.
<process procedure definitions>+= (U->) [<-D]
static void reschedule(void) {
ptab_iter end = ptab.end();
ptab_iter next_process;
if (idle_process->status == proc_executing) {
next_process = find_if(ptab.begin(), end, readyp);
if (next_process != end) {
idle_process->status = proc_ready;
load_cpu(next_process);
}
}
else {
next_process = find_if(ptab.begin(), end, runningp);
if (next_process == end) {
next_process = find_if(ptab.begin(), end, readyp);
if (next_process == end)
panic("can't find a ready process in process::reschedule()");
load_cpu(next_process);
}
}
if ((idle_process->status == proc_executing) && process::done() && disk::done())
process::halt();
}
Defines reschedule (links are to index).
Create a process from the program loaded into allocated space given by sc.
The new process is ready to run. The initial value of the PC is one past the
start of the program to skip over the program size value (however, the size
value is part of the program, so the base register should be set to the
start of the program).
<process interface definitions>= (U->) [D->]
void add(const storage::chunk & sc) {
process_table_entry new_pte;
const address a = storage::chunk_address(sc);
new_pte.registers[base_register] = a;
new_pte.registers[top_register] =
a + storage::chunk_size(sc)*disk_block_size;
new_pte.registers[pc_register] = a + 1;
new_pte.registers[sw_register] = 0;
new_pte.sc = sc;
ptab.push_front(new_pte);
ready(new_pte.id);
}
Defines process::add (links are to index).
Block the currently running process and start another.
<process interface definitions>+= (U->) [<-D->]
id block(void) {
running_process->save_state();
running_process->status = proc_blocked;
id pid = running_process->id;
reschedule();
return pid;
}
Defines process::block (links are to index).
The process manager's done when the idle process is the only process left to
manage. However, that doesn't mean execution is done because the disk
may still be at work loading programs.
<process interface definitions>+= (U->) [<-D->]
bool done(void) {
return (ptab.size() == 1);
}
Defines process::done (links are to index).
The only resource held by an exiting process is its allocated storage, which is
returned to the storage manager. Poke the disk in case it's suspended program
loading until more space has been freed.
<process interface definitions>+= (U->) [<-D->]
void exit(void) {
debugp(dbp_execute, "At time %d, process %d exits.\n",
read_clock(), running_process->id);
storage::release(running_process->sc);
ptab.erase(running_process);
reschedule();
disk::poke();
}
Defines process::exit (links are to index).
Halting the system has pie-like easiness.
<process interface definitions>+= (U->) [<-D->]
void halt(void) {
store_mem(halt_register, 0, halt);
}
Defines process::halt (links are to index).
The process manager initializes by defining and running the idle process, which
is a permanent resident of the process table.
<process interface definitions>+= (U->) [<-D->]
void init(void) {
process_table_entry idle_pte;
idle_pte.status = proc_ready;
idle_pte.registers[pc_register] = idle_start;
idle_pte.registers[base_register] = idle_start;
idle_pte.registers[top_register] = idle_end;
idle_pte.registers[sw_register] = 0;
idle_process = ptab.insert(ptab.begin(), idle_pte);
load_cpu(idle_process);
}
Defines process::init (links are to index).
Store a value in one of a process's saved registers.
<process interface definitions>+= (U->) [<-D->]
void put_register(id pid, unsigned r, word v) {
assert(r < next_register);
ptab_iter pti = find_proc(pid);
pti->registers[r] = v;
}
Defines process::put_register (links are to index).
When changing a process's status to ready, be sure to re-check the
process-table to see if the new process can run immediately.
<process interface definitions>+= (U->) [<-D]
void ready(id pid) {
find_proc(pid)->status = proc_ready;
reschedule();
}
Defines process::ready (links are to index).
<process.h>=
#ifndef _process_h_defined_
#define _process_h_defined_
#include "storage.h"
namespace process {
<process interface declarations>
};
#endif
<process.cc>=
#include <algorithm>
#include <list>
#include <functional>
#include "process.h"
#include "disk.h"
#include "storage.h"
#include "os.h"
<process data structures>
<process procedure definitions>
namespace process {
<process interface definitions>
}
Defines process.cc, process.h (links are to index).
Because this version of the operating system doesn't make the
disk available to the user processes, the only thing the code managing the disk
has to do is to read programs into User Space, an activity which doesn't
require too much in the way of an interface.
The init() procedure initializes the disk and begins program reading. The
done() procedure returns true when all programs have been read from disk;
if programs remain on disk to be read, done() returns false.
The disk code tries to read as many programs as it can as soon as it can;
ideally, it would read all the programs on disk at one go. However, if there's
more programs on disk than can fit in User Space, then the disk code has to
pause until more space is freed up. The poke() routine, when called, tries
to re-start program reading if it's been stalled; it's usually called after a
process has exited and freed up some User Space.
<disk interface declarations>= (U->)
void init(void);
void poke(void);
bool done(void);
On disk initialization, the next disk block to read is the first block on the
disk, no program reading is currently being done, and not all programs have
been read.
<disk interface definitions>= (U->) [D->]
void init(void) {
next_block_to_read = 0;
program_reading_done = false;
program_being_read = false;
poke();
}
Defines disk::init (links are to index).
If there's more programs to read and reading isn't in progress, then start
another read. Otherwise, either there's no more programs to read or a read is
in progress; in which case there's no reason to start another read.
<disk interface definitions>+= (U->) [<-D->]
void poke(void) {
if (!program_reading_done && !program_being_read)
read_next_program();
}
Defines disk::poke (links are to index).
The disk is done of program reading is done.
<disk interface definitions>+= (U->) [<-D]
bool done(void) {
return program_reading_done;
}
Defines disk::done (links are to index).
Handle a disk-interrupt that is the result of reading in a program's block. If
all the program's blocks have been read in, then the program is ready to run;
hand it off to the process manager and go read then next program. Otherwise,
schedule a disk-read for the next block in the program.
<disk procedure definitions>= (U->) [D->]
static void read_rest_program(void) {
check_disk_error(read_rest_program);
if (++program_blocks_read_in == blocks_in_program) {
process::add(program_chunk);
program_being_read = false;
disk::poke();
}
else {
disk_read(read_rest_program);
next_block_to_read++;
next_program_address += disk_block_size;
}
}
Defines read_rest_program (links are to index).
Handle the disk interrupt that results from reading a program's first block.
If the program size is zero, there's no more programs on the disk and program
reading is over. If there's no more process to run, then execution's over too.
If the program's too big for its allocated space, then suspend program reading
until more space frees up. Otherwise, trim the allocated space to the
required amount and read in the rest of the program's blocks. Note this
involves calling read_rest_program() as a continuation of the interrupt
processing started by handle_first_block().
<disk procedure definitions>+= (U->) [<-D->]
static void handle_first_block(void) {
check_disk_error(handle_first_block);
word w;
fetch_mem(next_program_address, w, handle_first_block);
if (next_block_to_read + static_cast<unsigned>(w) > disk_size)
panic("invalid program size %d in handle_first_block()", w);
else
if (w == 0) {
storage::release(program_chunk);
program_reading_done = true;
program_being_read = false;
if (process::done())
process::halt();
return;
}
if (static_cast<unsigned>(w) > storage::chunk_size(program_chunk)) {
storage::release(program_chunk);
program_being_read = false;
}
else {
storage::adjust(program_chunk, w);
program_blocks_read_in = 0;
blocks_in_program = w;
mass.memory->set_ihandler(disk_i, read_rest_program);
next_program_address += disk_block_size;
next_block_to_read++;
read_rest_program();
}
}
Defines handle_first_block (links are to index).
Try to read another program. If the next disk block to read is larger than the
disk, then there's no more programs to read. Otherwise, allocate the largest
chunk of free space available. If there's no free space available, then don't
do any reading. If there if there is free space available, then read in the
program's first block.
<disk procedure definitions>+= (U->) [<-D]
static void read_next_program(void) {
if (next_block_to_read >= disk_size)
program_reading_done = true;
else {
program_chunk = storage::max_chunk();
if (storage::chunk_size(program_chunk) > 0) {
assert(!program_being_read);
program_being_read = true;
next_program_address = storage::chunk_address(program_chunk);
disk_read(read_next_program);
mass.memory->set_ihandler(disk_i, handle_first_block);
}
}
}
Defines read_next_program (links are to index).
Check for a disk-io error on behalf of _caller and die if found.
<disk macro definitions>= (U->) [D->]
#define check_disk_error(_caller) \
do { \
word w; \
fetch_mem(disk_status_register, w, _caller); \
if (w != status::ok) \
panic("disk read error %d in " #_caller "()", w); \
} while (false)
Defines check_disk_error (links are to index).
Issue a disk read on behalf of _caller.
<disk macro definitions>+= (U->) [<-D]
#define disk_read(_caller) \
do { store_mem(disk_block_register, next_block_to_read, _caller); \
store_mem(disk_address_register, next_program_address, _caller); \
store_mem(disk_command_register, disk_io::read, _caller); } while (false)
Defines disk_read (links are to index).
<disk.h>=
#ifndef _disk_h_defined_
#define _disk_h_defined_
namespace disk {
<disk interface declarations>
};
#endif
<disk.cc>=
#include "os.h"
#include "disk.h"
#include "storage.h"
#include "process.h"
// If true, there's no more programs to read.
static bool program_reading_done;
// If true, a program's being read in;
static bool program_being_read;
// The next disk read reads the block at next_block_to_read;
static unsigned next_block_to_read;
// The current program being read contains blocks_in_program blocks.
static unsigned blocks_in_program;
// program_blocks_read_in of the blocks in the current program being read
// have been read in.
static unsigned program_blocks_read_in;
// The next disk block read gets stored at the address given by
// next_program_address.
static address next_program_address;
// The chunk of user-space storage into which the program is being read.
storage::chunk program_chunk;
<disk macro definitions>
<disk procedure definitions>
namespace disk {
<disk interface definitions>
};
Defines disk.cc, disk.h (links are to index).
The message pool has a simple interface, which is one of the advantages of
message passing as a synchronization mechanism. Note, however, that the
get() procedure doesn't return a value, which suggests the message-pool
implementation will be a bit less simple than is the interface.
<message-pool interface declarations>= (U->)
void put(word tag, word data);
void get(word tag);
Within the message-pool implementation, a message is represented as a
(tag, data) pair.
<message-pool data structures>= (U->) [D->]
typedef std::pair<word, word> msg;
Defines msg (links are to index).
Messages sent but not yet received are stored in a list.
<message-pool data structures>+= (U->) [<-D->]
static std::list<msg> mpool;
typedef std::list<msg>::iterator mpool_iter;
static inline word msg_tag(const msg & m) { return m.first; }
static inline word msg_data(const mpool_iter & mi) { return mi->second; }
Defines mpool, mpool_iter, msg_data, msg_tag (links are to index).
A process that is blocked because its trying to receive a message that hasn't
yet been sent is represented by the pair (i, t), where i is the
process's id and t is the tag of the message being waited for.
<message-pool data structures>+= (U->) [<-D->]
typedef std::pair<process::id, word> waiter;
Defines waiter (links are to index).
Waiting processes are put in the waiting list.
<message-pool data structures>+= (U->) [<-D]
static std::list<waiter> waiters;
typedef std::list<waiter>::iterator wlist_iter;
static inline process::id waiter_id(const wlist_iter & wi) { return wi->first; }
static inline word waiter_tag(const waiter & w) { return w.second; }
Defines waiter_id, waiters, waiter_tag, wlist_iter (links are to index).
Given the container values and the matching function match over
elements of values, return true if values contains an element that
matches on the value tag; return false otherwise. If values does have
a match, set i to point to the matching element; otherwise, i contains
an undefined value.
<message-pool procedure definitions>= (U->) [D->]
template<typename container_type, typename tag_type>
bool find_value(
container_type & values,
bool (* match)(typename container_type::value_type, tag_type),
tag_type tag,
typename container_type::iterator & i)
{
typename container_type::iterator e = values.end();
i = std::find_if(values.begin(), e, bind2nd(ptr_fun(match), tag));
return i != e;
}
Defines find_value (links are to index).
Search the message pool for a message with tag t. If such a message
exists, set mi to point to it and return true. If no such message exists,
return false.
<message-pool procedure definitions>+= (U->) [<-D->]
static bool msg_match(const msg m, word t) {
return msg_tag(m) == t;
}
static bool find_msg(word t, mpool_iter & mi) {
return find_value(mpool, msg_match, t, mi);
}
Defines find_msg, msg_match (links are to index).
Search the list of waiting processes for a process waiting for a message with
tag t. If such a process exists, set wi to point to it and return
true. If no such process exists, return false.
<message-pool procedure definitions>+= (U->) [<-D]
static bool waiter_match(const waiter w, word t) {
return waiter_tag(w) == t;
}
static bool find_waiter(word t, wlist_iter & wi) {
return find_value(waiters, waiter_match, t, wi);
}
Defines find_waiter, waiter_match (links are to index).
Receive from the message pool a message having tag t. If such a message
exists, remove it from the pool and store the associated data in the calling
user-process's register 2. Otherwise, block the calling user process until the
message shows up.
<message-pool interface definitions>= (U->) [D->]
void get(word t) {
mpool_iter mi;
if (find_msg(t, mi)) {
store_mem(2, msg_data(mi), msg_pool::get);
debugp(dbp_msg, "At time %4d, message (%d, %d) removed from the pool.\n",
read_clock(), t, msg_data(mi));
mpool.erase(mi);
}
else
waiters.push_back(waiter(process::block(), t));
}
Defines msg_pool::get (links are to index).
Put the message having tag t and data d into the message pool.
However, before doing that, search the list of waiting processes to see if
there's a waiter for this message. If so, skip the message pool and transfer
the data directly to the waiting process and wake it up; otherwise, add the
message to the message pool.
<message-pool interface definitions>+= (U->) [<-D]
void put(word t, word d) {
wlist_iter wi;
debugp(dbp_msg, "At time %4d, message (%d, %d) put into the pool.\n",
read_clock(), t, d);
if (find_waiter(t, wi)) {
const process::id pid = waiter_id(wi);
process::put_register(pid, 2, d);
process::ready(pid);
waiters.erase(wi);
debugp(dbp_msg, "At time %4d, message (%d, %d) removed from the pool.\n",
read_clock(), t, d);
}
else
mpool.push_back(msg(t, d));
}
Defines msg_pool::put (links are to index).
<mpool.h>=
#ifndef _mpool_h_defined_
#define _mpool_h_defined_
#include "system.h"
namespace msg_pool {
<message-pool interface declarations>
};
#endif
<mpool.cc>=
#include <list>
#include <functional>
#include "mpool.h"
#include "process.h"
#include "os.h"
<message-pool data structures>
<message-pool procedure definitions>
namespace msg_pool {
<message-pool interface definitions>
};
Defines mpool.cc, mpool.h (links are to index).
The operating system's storage management characteristics are simple: programs
don't change size during execution, program size can be determined statically
before execution starts, and allocated space must be contiguous.
Correspondingly, the data representation for allocated storage is simple too.
Each chunk of user space allocated to a program is represented by a pair of
numbers giving the lowest user-space address and size of the chunk in disk
blocks.
<storage-management interface definitions>= (U->) [D->]
typedef std::pair<address, unsigned> chunk;
inline address chunk_address(const chunk & sc) {
return sc.first;
}
inline unsigned chunk_size(const chunk & sc) {
return sc.second;
}
Defines chunk, chunk_address, chunk_size (links are to index).
The storage manage needs to be initialized with both the lowest address
and size in disk blocks of the allocatable storage.
<storage-management interface definitions>+= (U->) [<-D->]
void init(address base, unsigned size);
The trick to allocating storage is that the program size is unknown before the
first block is read in, and the first block can't be read in until some storage
is allocated for the program (That last bit isn't true, because the operating
system could always read the first block into a buffer allocated in system or
device space. However, to do so would require either another disk read or,
more likely, a copy into user space. Both are unattractive alternatives
because of extra time they'd take.)
The way out of this trick is to allocate the largest contiguous chunk of
storage available. If the next program's larger than the chunk, it can't be
read in anyway.
<storage-management interface definitions>+= (U->) [<-D->]
chunk max_chunk(void);
Once the program size is known, so is the amount of unneeded space in the
allocated storage chunk. To improve storage utilization, it should be possible
to adjust an allocated chunk to an exact fit (relative to block size),
returning the unneeded space to the free list.
<storage-management interface definitions>+= (U->) [<-D->]
void adjust(chunk & sc, unsigned new_size);
And it should be possible to return an allocated chunk to the free-storage
<storage-management interface definitions>+= (U->) [<-D]
void release(const chunk & sc);
Allocatable storage is organized into a sequence of blocks, each the size of a
disk block. The whole of allocatable store is represented by a bit map, where
bit i represents the availability of storage block i.
base_address keeps track of the lowest address in allocatable storage.
<allocatable-storage data structures>= (U->) [D->]
static std::vector<bool> free_blocks;
static address base_address;
Defines base_address, free_blocks (links are to index).
The internal representation of allocated storage is similar to the external
representation. The only difference is using an index (into the bit map)
instead of an address to indicate the start of the allocation. To avoid
confusion between the representations, the internal representation is called an
index range, and the external representation is called a storage chunk.
<allocatable-storage data structures>+= (U->) [<-D->]
typedef std::pair<unsigned, unsigned> index_range;
#define range_start(_r) (_r).first
#define range_size(_r) (_r).second
Defines index_range, range_size, range_start (links are to index).
There needs to be a way of converting between the internal and external
representations of allocated storage.
<allocatable-storage data structures>+= (U->) [<-D]
static index_range sc2ir(const storage::chunk & sc) {
return std::make_pair(
(storage::chunk_address(sc) - base_address)/disk_block_size,
storage::chunk_size(sc));
}
static storage::chunk ir2sc(const index_range & ir) {
return std::make_pair(base_address + range_start(ir)*disk_block_size,
range_size(ir));
}
Defines ir2sc, sc2ir (links are to index).
Return the next range of free blocks at or to the right of the block at start.
Return a range of zero length if there's no free blocks.
<storage routine definitions>= (U->) [D->]
static index_range find_free_range(unsigned start) {
const unsigned fbs = free_blocks.size();
while ((start < fbs) && !free_blocks[start])
start++;
unsigned size = 0;
while ((start + size < fbs) && free_blocks[start + size])
size++;
return std::make_pair(start, size);
}
Defines find_free_range (links are to index).
Set the free-map bits in the index range ir to the value bv. Die if
any of the bits in the range are already equal to bv.
<storage routine definitions>+= (U->) [<-D]
static void set_range(const index_range & ir, bool bv) {
const unsigned e = range_start(ir) + range_size(ir);
assert(e <= free_blocks.size());
for (unsigned i = range_start(ir); i < e; i++) {
assert(free_blocks[i] != bv);
free_blocks[i] = bv;
}
}
#define release_range(_ir) set_range(_ir, true)
#define allocate_range(_ir) set_range(_ir, false)
Defines allocate_range, release_range, set_range (links are to index).
The storage manager is initialized with the start (lowest address) and size of
the storage area to be managed. Initially, all storage is free.
<storage namespace definitions>= (U->) [D->]
void init(address start, unsigned size) {
assert(size > 0);
base_address = start;
while (size-- > 0)
free_blocks.push_back(true);
}
Defines storage::init (links are to index).
Return the largest contiguous chunk of unallocated storage.
<storage namespace definitions>+= (U->) [<-D->]
chunk max_chunk(void) {
index_range free_range = find_free_range(0);
index_range ir = free_range;
while (true) {
ir = find_free_range(range_start(ir) + range_size(ir) + 1);
if (range_size(ir) == 0) break;
if (range_size(ir) > range_size(free_range))
free_range = ir;
}
allocate_range(free_range);
return ir2sc(free_range);
}
Defines storage::max_chunk (links are to index).
Shrink the allocated storage sc to new_size blocks, returning the
unused blocks to the free list; die if new_size is larger than sc's
current size. sc is modified to reflect its new size.
<storage namespace definitions>+= (U->) [<-D->]
void adjust(chunk & sc, unsigned new_size) {
index_range ir = sc2ir(sc);
assert(range_size(ir) >= new_size);
range_start(ir) += new_size;
range_size(ir) -= new_size;
release_range(ir);
sc = chunk(chunk_address(sc), new_size);
}
Defines storage::adjust (links are to index).
Return the allocated storage sc to the free list.
<storage namespace definitions>+= (U->) [<-D]
void release(const chunk & sc) {
release_range(sc2ir(sc));
}
Defines storage::release (links are to index).
A quick check to make sure the storage-management code is working without
problems.
<storage testing code>= (U->)
#ifdef TESTING_STORAGE
// g++ -DTESTING_STORAGE -o testing-storage -ansi -pedantic -Wall -I ../arch storage.cc
int main() {
storage::init(1024, 32);
storage::chunk sc = storage::max_chunk();
assert(storage::chunk_address(sc) == 1024);
assert(storage::chunk_size(sc) == 32);
storage::chunk sc2 = storage::max_chunk();
assert(storage::chunk_size(sc2) == 0);
}
#endif
<storage.h>=
#ifndef _storage_h_defined_
#define _storage_h_defined_
#include <algorithm>
#include "system.h"
namespace storage {
<storage-management interface definitions>
};
#endif
<storage.cc>=
#include <vector>
#include "storage.h"
#include <cassert>
<allocatable-storage data structures>
<storage routine definitions>
namespace storage {
<storage namespace definitions>
};
<storage testing code>
Defines storage.cc, storage.h (links are to index).
Some odds and ends useful to all code throughout the operating system.
<os.h>=
#ifndef _os_h_defined_
#define _os_h_defined_
#include <iostream>
#include "mass.h"
#include "utils.h"
#define fetch_mem(_a, _v, _w) \
do if (mem_fetch(_a, _v) != Memory::ok) \
panic(#_a " fetch failed in " #_w "()"); while (false)
#define store_mem(_a, _v, _w) \
do if (mem_store(_a, _v) != Memory::ok) \
panic(#_a " store failed in " #_w "()"); while (false)
#define dbp_execute dbp_f29
#define dbp_msg dbp_f28
extern unsigned read_clock(void);
#endif
Defines dbp_execute, dbp_msg, fetch_mem, os.h, store_mem (links are to index).
- <allocatable-storage data structures>: D1, D2, D3, U4
- <disk interface declarations>: D1, U2
- <disk interface definitions>: D1, D2, D3, U4
- <disk macro definitions>: D1, D2, U3
- <disk procedure definitions>: D1, D2, D3, U4
- <
disk.cc>: D1
- <
disk.h>: D1
- <interrupt handlers>: D1, D2, U3
- <
interrupts.cc>: D1
- <message-pool data structures>: D1, D2, D3, D4, U5
- <message-pool interface declarations>: D1, U2
- <message-pool interface definitions>: D1, D2, U3
- <message-pool procedure definitions>: D1, D2, D3, U4
- <
mpool.cc>: D1
- <
mpool.h>: D1
- <
os.h>: D1
- <process data structures>: D1, D2, D3, U4
- <process interface declarations>: D1, D2, D3, D4, D5, U6
- <process interface definitions>: D1, D2, D3, D4, D5, D6, D7, D8, U9
- <process procedure definitions>: D1, D2, D3, D4, U5
- <
process.cc>: D1
- <
process.h>: D1
- <storage namespace definitions>: D1, D2, D3, D4, U5
- <storage routine definitions>: D1, D2, U3
- <storage testing code>: D1, U2
- <
storage.cc>: D1
- <
storage.h>: D1
- <storage-management interface definitions>: D1, D2, D3, D4, D5, U6
- allocate_range: D1, U2
- base_address: D1, U2, U3
- check_disk_error: U1, U2, D3
- chunk: U1, U2, U3, U4, D5, U6, U7, U8, U9, U10, U11, U12, U13
- chunk_address: U1, U2, D3, U4, U5, U6
- chunk_size: U1, U2, U3, D4, U5, U6
- dbp_execute: U1, U2, D3
- dbp_msg: U1, U2, D3
- disk.cc: D1
- disk::done: U1, D2
- disk.h: U1, U2, D3
- disk::init: U1, D2
- disk::poke: U1, D2, U3
- disk_read: U1, U2, D3
- fetch_mem: U1, U2, U3, U4, U5, D6
- find_free_range: D1, U2
- find_msg: D1, U2
- find_proc: D1, U2, U3
- find_value: D1, U2, U3
- find_waiter: D1, U2
- free_blocks: D1, U2, U3, U4
- handle_first_block: D1, U2
- idle_process: D1, U2, U3
- index_range: D1, U2, U3, U4, U5, U6
- interrupts.cc: D1
- ir2sc: D1, U2
- load_cpu: D1, U2, U3
- mpool: U1, D2, U3, U4, U5, U6
- mpool.cc: D1
- mpool.h: U1, D2
- mpool_iter: D1, U2, U3
- msg: D1, U2, U3, U4
- msg_data: D1, U2
- msg_match: D1
- msg_pool::get: U1, D2
- msg_pool::put: U1, D2
- msg_tag: D1, U2
- os.h: U1, U2, U3, U4, D5
- process::add: D1, U2
- process::block: D1, U2
- process.cc: D1
- process::done: U1, D2, U3
- process::exit: U1, D2
- process.h: U1, D2, U3, U4
- process::halt: U1, D2, U3
- process::id: D1, U2, U3, U4, U5, U6
- process::init: U1, D2
- process::put_register: D1, U2
- process::ready: D1, U2
- process_status: D1, U2
- process_table: D1
- process_table_entry: D1, U2, U3, U4, U5, U6
- ptab: D1, U2, U3, U4, U5, U6, U7
- ptab_iter: D1, U2, U3, U4, U5
- range_size: D1, U2, U3, U4, U5
- range_start: D1, U2, U3, U4, U5
- read_next_program: U1, D2
- read_rest_program: D1, U2
- readyp: D1, U2
- reboot_ih: D1
- release_range: D1, U2, U3
- reschedule: D1, U2, U3, U4
- restore_state: D1, U2
- runningp: D1, U2
- running_process: D1, U2, U3, U4
- save_state: D1, U2
- sc2ir: D1, U2, U3
- set_range: D1
- storage::adjust: U1, D2
- storage.cc: U1, D2
- storage.h: U1, U2, U3, U4, D5
- storage::init: U1, D2, U3
- storage::max_chunk: U1, D2, U3
- storage::release: U1, U2, D3
- store_mem: U1, U2, U3, U4, U5, D6
- syscall_ih: D1, U2
- waiter: D1, U2, U3, U4
- waiter_id: D1, U2
- waiter_match: D1
- waiters: D1, U2, U3, U4
- waiter_tag: D1, U2
- wlist_iter: D1, U2, U3
This page last modified on 5 December 2001.