
Semantic Web for Collaborative Software Processes
Raman Kannan, Rajiv Rodrigues, Joe O'Conner and Puran Nebhani
kannan@moncol.monmouth.edu
Center for Technology Transfer and Development
Monmouth University
West Long Branch, NJ 07764
Abstract
Software Processes are inherently group oriented and there is a vast amount of legacy software base. The World Wide Web has proven to be a highly usable technology. However, WWW is not designed to be a multi-user application and the WWW Browsers are HTML and document centric. In this article we present IDAM --an active document archive management -- to manage software assets using WWW, on demand. Furthermore, we propose, integrating multi-user services into WWW using existing technologies.
Introduction
The idea of using computers and software tools to improve the quality of software products and the efficiency of related processes is anything but new (See [1] innovative research report and [2] special interest groups on software processes). Notwithstanding, the costs associated with software products and processes have continued to rise, primarily because: (1) software processes are inherently complex involving people, product and processes; (2) encompassing numerous orthogonal and competing disciplines, technologies, forces and perspectives; and (3) connected to each other explicitly as well as in non-intuitive ways as shown in Figure 1.
In particular, software artifacts, (unlike most other human engineered artifacts -- a concrete building -- for example) are highly malleable and can be reconfigured in unknown ways and the software processes are inherently group oriented. In this report we present our approach and experience in constructing "yet another" innovative tool to assist in collaborative software engineering.
Software Processes
Software process is defined to be "collection of activities that begin with the identification of a need and concludes with the retirement of the software product that satisfies the need" [3]. Several life cycle models have been proposed [See [4] for an overview] and in figure 2, we propose a variation of software processes explicitly recognizing the relationship between cooperative problem solving and software engineering.
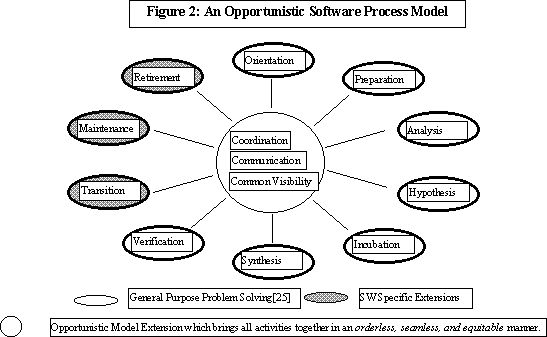
The model we propose is fundamentally different in that: (1) there is no sequence or order except that phases become active whenever there is an opportunity to make a positive contribution; (2) groupware essentials [5] [coordination, communication and common visibility] are explicitly included as a binding mechanism between all the phases ; and (3) the phases are equitable. Note that these tasks may be carried out in parallel. In other words, "collaboration" is essential during the entire duration and groupware--tools that support group work--must meet these basic requirements: (1) be conducive to all the phases; (2) support "seamless" transition from one phase to any other phase whenever needed; and (3) manage simultaneous activities.
In the following sections we present: (1) the relevance of WWW with respect to software processes; (2) identify impediments to WWW enabled software processes; (3) IDAM, a framework to address these issues; (4) Outstanding Issues; (5) the relevance of groupwork to software processes; and (6) plausible future action.
Human Computer Interaction: Relevance of Software Processes and WWW
The software processes can be significantly improved using WWW (and related tools) for two compelling reasons: (1) The Web Browsers[6] and the World Wide Web [7] may very well be the only candidate for an universal desktop [8]. Why does the WWW thus refute the 500 year old Machiavellian observation?. Because the hypermedic navigational framework radically augments our ability to interact with the computer in intuitive ways ("Usability"); and (2) The ability to browse/navigate in hypermedic space is particularly significant for software artifacts and associated processes because they are intricately connected in non-intuitive ways. The usefulness of semantic information and being able to discover semantic relationship is presented in [11]. The need for analyzing the static dependencies amongst software components and the usefulness of such static analysis tools are presented in [12]. In [13] the relationship between comprehension and testing and the resulting synergistic benefits are discussed. In [14] it is shown that software engineers prefer to organize and manipulate software components consistent with the programming language semantics rather than the linear operating system supported ASCII file structures. Furthermore, component archival and management as an essential requirement for reuse is illustrated in [15][16]. A reuse repository implemented using the WWW Browser is discussed in [17]. In essence we believe that hypermedia and WWW technologies, in particular, will radically change the way we practice software having an impact on every aspect of software life cycle.
The Missing Link
The problem, however, is one of missing links. Software assets abound and the WWW technologies are very successful. Yet, existing software base cannot be readily browsed using the WWW browser (leveraging the hypermedic capabilities) as is, because the components (and the relationship amongst them) are not codified in HTML format. Furthermore, programming language compilers will not tolerate embedded HTML tags. This is a major problem and the islands of automation of the 1980s have mutated into islands of incompatible formats in the 90s. Given that software maintenance accounts anywhere from 40% to 80% of the total software product cost [18], the impact of a tool as envisioned here will be significant.
Info-Dam (I-DAM): The Metaphor and the Proposed Architecture
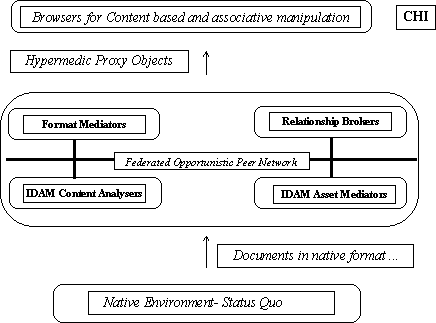
Info-dam --an active document archive management -- is a general purpose framework to harness the true power of very large persistent information bases. Info-dams will be effective in controlling and managing information in the digital universe much as dams are effective in controlling and harnessing perennial rivers in the natural universe. As shown in Figure 3, Info-Dam is a collection of independent agents that cooperatively facilitate archival, retrieval and navigation, at the semantic level.
Info-DAM: Strategy
Our strategy is to divide the documents into structured and unstructured assets, employ suitable techniques to identify semantic relationships and incorporate the appropriate hypermedic links, automatically. Programming Language constructs obey well-defined contextual semantics and syntax. These are what we call structured documents. Using the grammar we generate the set of candidate symbols. IDAM candidate symbols include all user defined external references excluding keywords and comments. Then using the language semantics (specification units of the language) discover the exact location of these external symbols. Consider the C Programming Language [19]. First we collect all the candidate symbols (function names, variables, types, include files etc.). Given a function name, to locate the function definition, we search the source directories in context and language specific locations (the include files (system wide) in /usr/include directory). Similarly, given variable declarations, we recognize the type and locate the type definition using the above searching order. Thus, we establish the relationship between language components within the source files. The format mediators use formatting rules to generate client compliant files (currently WWW/HTML compliant files). The original files are left unchanged. We have implemented a prototype (for Language C, VHDL) using commonly available text processing tools such as tcl, perl and awk.
For processing unstructured assets we are evaluating a hybrid approach incorporating various techniques (indexing engines at the lowest level, case based reasoning at the highest level). We are experimenting with Orbeline CORBA services to manage documents in a networked enterprise. We are concentrating on techniques for intranet collaboration to avoid an open-ended search space like the internet. End users browse the HTML counterparts using readily available Web Browsers.
There are numerous outstanding issues. For example, certain higher level language semantics cannot be fully discovered, using static analysis. A case in point is polymorphism (and or dynamic binding). The effect of these language constructs are observable only during runtime and discovering proper relationships using syntax (static analysis) is not trivial if not impossible.
Groupware and Software Processes
Software processes are group activities. It has been estimated that in large projects team efforts constitute 70% of the total time [20] and 85% of the total cost is spent on group activities [21]. In [10] the relationship between coordination techniques and the extent to which these techniques were used by software engineers is presented. The need for coordinated configuration management in a distributed environment and the benefits are illustrated in [22]. In essence every aspect of the software process is a group effort. Consequently, groupware is essential for effective software processes.
Supporting a Group (WWW Issues)
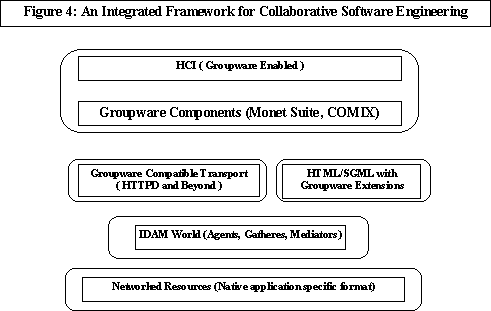
The legacy WWW medium is an excellent foundation for the individual. However, extensions have to be incorporated for multi-user scenarios. Support for direct communication between individuals (in real time multimedia), coordination, and sharing applications is required. For example, consider code walkthrough, which is a "static analysis" for logic and consistency. While the IDAM Agents allow software to be incorporated into the WWW medium, on demand, automatically, the browsers and the HTTP must support a group of code reviewers to browse the software components synchronously and in an orderly manner. We propose a layered architecture as shown in Figure 4.
Issues
There are numerous unanswered questions and some (not exhaustive) in particular are :
Summary
In this article we have discussed the relationship between software processes and two emergent technologies namely, groupware and hypermedia. We have presented a fundamentally different model for software process as a collection of orderless, opportunistic processes mediated by a collaborative framework. In other words we posit that (1) software processes and collaborative work are inseparable and (2) any observed ordering is purely opportunistic.
We have presented a survey of research reports in support of our claim that hypermedia and computer support for collaborative work are desirable for effective software practices. We have presented the Info-DAM framework to incorporate potentially unlimited software repositories into the WWW and possible ways to extend the web to meet demands of this highly collaborative domain.
Acknowledgments
A research stipend from ASSET Corporation, Holmdel, NJ, an equipment subsidy from CTTD, and graduate research stipends from the Graduate School are acknowledged.. Rajiv Rodrigues is primarily interested in processing structured documents and HTML generators. Joe O'Conner is pursuing a Masters thesis on classification schemes for unstructured documents. Puran Nebhani is experimenting with WWW and CORBA integration, appropriate IDL definitions. DNA Laboratory is most unfunded at this time and engages in these activities for the sheer challenge of it.
References
[1] Prasun Dewan and John Riedel, Toward Computer Supported Concurrent Software Engineering, IEEE Computer, January 1993, 17-17.
[2] "Working Group Report on Process", Edited by Paolo Ciancarini, V. Juggy Jagannathan, Mark Klein, and Wil van der Aalst, in Proceedings of the Fourth WETICE Conference, April 20-22 1995, 8-11. (IEEE Computer Press)
[3] Bruce I. Blum, "Software Engineering: A Holistic View", Oxford Press, 1992.
[4] Edward V. Berard, "Life Cycle Approaches", Chapter 4 in "Essays on Object-Oriented Software Engineering", Prentice Hall, 1993.
[5] Computer Support for Concurrent Engineering, "Guest Editor's Introduction", IEEE Computer January 1993, 12-16.
[6] Hal Berghel, "The Client Side of the World Wide Web", CACM, January 1996, 30-40.
[7] Berners-Lee, Tim, et. al., "The World Wide Web", C ACM, August 1994, pp. 76-82.
[8] Dave Power, "The Future of Software" in "Where is Software Headed? A Virtual Roundtable", IEEE Computer, August 1995, 21-22.
[9] Roger S. Pressman, in "Software Engineering: A Practitioner's Approach", Pg. 32, McGraw Hill, 1987.
[10] Robert E. Kraut and Lynn A. Streeler, "Coordination in Software Engineering", CACM, March 1995, 69-81.
[11] Sandra Heiler, "Semantic Interoperability", Research Directions in Software Engineering, ACM Computing Surveys, June 1995, 271-273.
[12] Yih-Farn Chen, "Reverse Engineering" in Practical Reusable Software. Editors Balachander Krishnamurthy, Wiley and Sons.
[13] Thomas J McCabe and Arthur H Watson, "Combining comprehension and testing in Object Oriented Development", Object Magazine, March-April 1994, 63-66.
[14] Joseph Dumas and Paige Parsons, "Discovering the Way Programmers Think About New Programming Environments", CACM, June 1995, 45-56. Source code organizing.
[15] David Reed, Tools for Software Reuse, Object Magazine, February 1995, 63-67.
[16] Charles W. Krueger, Software Reuse, ACM Computing Surveys, June 1992, 131-183.
[17] Jeffrey S. Poulin and Keith J. Werkman, "Melding Structured Abstracts and the World Wide Web for Retrieval of Reusable Components", in Proceedings of the ACM SIGSOFT "Symposium on Symposium Reusability", Seattle, Washington, April 28-30, 1995, 160-168.
[18] Don Coleman, et. al., Using Metrics to Evaluate Software System Maintainability, IEEE Computer, August 1994, 44-49.
[19] Brian Kernigan and Dennis Richie, "The C Programming Language", Prentice Hall.
[20] DeMarco T. and Lister T., Peopleware, Dorset House, New York, 1987.
[21] Jones, T.C. Programming Productivity, McGraw Hill, New York, 1986.
[22] David Baum, Unify Dispersed Development Teams, Datamation, August 15, 1995, 37-39.
[23] Jintae Lee, "Collaborative Software Resource Clearinghouse", Position Papers from the CSCW' 94 Workshops, SIGOIS Bulletin, December 1994, 13-14.
[24] K.G. Pankaj and W. Scacchi, "On designing hypertext systems for information management in software engineering", Hypertext 87 Papers, November 1987.
[25] Alex Osborn, "Problem Solving--the best of all creative exercises", in "Wake Up Your Mind", 1952, DELL Publishing Co., Inc., New York, N 10017.