Raman Kannan
Bo Cao, Rajesh Rao, Joe Occoner and Zhen Chen
DNA Laboratory
Software Engineering Department
Bandish Chitre
Electrical Engineering Department
Monmouth University
West Long Branch, NJ 07733
Abstract
In this article we introduce Disha an environment in which software professionals can discover software component from around the world and browse software components in an highly intuitive manner. Disha is comprised of independent softbots that: (1) perpetually search software sites on the internet and catalog the components found; (2) proactively offer helpful cues regarding software components that may be immediately used as is or as a learning aid; and (3) fetch and present such software components in an intuitive manner. We use commonly available internet services, such as, simple mail transfer protocol (smtp), file transfer protocol (ftp), hypertext transfer protocol (http), WWW browser and other appropriate internet [1] services, indexing software (gais [2], glimpse [3]), and interpretive languages such as perl [4], java [5], tcl/tk/expect [6] to construct Disha environment.
Rationale
The evolution of internet as a mainstream communication medium has been super-accelerated with the advent of intuitive interface to the internet (WWW, email and other internet services). Vast amount of useful information assets are made available at ever increasing pace. But, what good is it if only we cannot use, all of it, at will, from anywhere, without having to go through a lot of technical wizardry if not painfully repetetive sequence of conversations with the system (mouse clicks, visiting pages etc...)? In essence: (1) there is a viable infrastructure; (2) vast amount of information assets; but (3) an acute lack of intuitive and effective access mechanisms. The existing access mechanisms do not scale with the size of the content. Our inability to exploit the internet resources has been the motivation behind our efforts in the IDAM project [7,8]. Our goal, in this project, is to integrate the various tools we have gathered (fabricated here or elsewhere) to:
While we focus on the internet in this report our ideas, approach and software services can be readily used in IP enabled intranets. Now we present a brief introduction to software construction and maintenance acitivities, operational perspective using use case scenarios (as to how a software professional might use Disha in their construction and maintenance efforts) and an architecture for the Disha Environment.
Software Construction and Maintenance
Software construction (development) and maintenance are two distinct phases within the software development life cycle [See standard text books on Software Engineering for other details]. During the construction phase software engineers implement a design specification in one or more programming languages such that all the details needed to execute the system are available. More often than not software engineers (in sharp contrast to hardward engineers) implement even well known design abstractions from scratch (reinventing the wheel). Consequently the cost to develop software has been increasing while hardware construction costs have been decreasing. Efforts to promote reuse using structured software repositories have not been successful and our premise is that the process of software reuse is perhaps more complicated than necessary. The Disha philosophy is to offer software cues about software components that exist elsewhere. The software engineer need not even be aware of the software component or the location where the software component resides. Thus, with Disha, we posit that software engineers under similar circumstance may now be willing to explore the possibility of using existing assets rather than reimplement them, because:
Disha in essence lessens the coginitive effort using much less restrictive procedures.
Software maintenance, on the other hand, is the process of evolving a software system after delivery: (1) to meet changing customer requirements; (2) to function in new hardware/software environments; and (3) to fix reported errors. It is estimated that a significant effort is spent on software maintenance compared to any other software life cycle activity and consequently even marginal increase in maintenance efficiency could result in significant reduction in software life cycle costs. However, most software engineering environments are not conducive to software maintenance. Software assets are partitioned based on programming language constructs while the assets are held in flat text files that do not preserve the syntactic and module information of the programming language. So during maintenance human engineers have to translate back and forth from a programming language context to the file layout context. In essence, comprehension, understandability and the ability to recall related software elements with ease are critical capabilities for software maintenance. Disha approach here is to reduce the coginitive effort required to navigate within a software repository exploiting the hypertext transfer protocol (HTTP) and HTML (browser) capabilities of the internet applications.
Now we present the details of the Disha solution from an operational perspective -- as to how end users may use the Disha system -- and architectural perspective -- as to how the Disha system is being assembled --.
The Disha Solution: Operational Perspective
The idea behind Disha is best explained using two use case scenarios centered around: (1) reuse -- Disha augmented software synthesis -- ; and (2) software maintenance -- Disha augmented software navigation and recall.
Disha Augmented Software Synthesis
Imagine a software engineer composing a solution using a web enabled editor. Let us assume that the design calls for opening a file using the native OS services -- the open system call--. As the engineer enters the symbol open, Disha proactively recalls other software components that also employ the open system call and presents visual cues. Disha visual cues are blinking folder icons that represent software components and these visual cues may be pursued to learn how to use such a function, by a single mouse click, in a user friendly manner. The user if not interested may simply ignore the visual cue offered by Disha and the visual cues fade out in time. However, when the user is not familiar with the -- open -- system call, the user may choose to pursue the visual cues offered by Disha. In other words, whenever, the user enters a program construct that is external to the language definition, typically a function name, Disha agents, search an existing database for software resources which include such a function. If a software resource is found a visual cue is offered as a HTML link. If the user pursues the visual cue then the resource is retrieved from the network and converted into HTML format so that the engineer can intuitively browse the software component. The engineer can now understand the exact conditions and the interface protocol with which the desired function is used. Furthermore, if appropriate the engineer may choose to incorporate the discovered resource. We call this --just in time-- reuse.
Disha Augmented Software Maintenance
The ability to browse/navigate in hypermedic space is particularly significant for software artifacts [9] and associated processes because they are intricately connected in non-intuitive ways. The usefulness of semantic information and being able to discover semantic relationship is presented in [10]. The need for analyzing the static dependencies amongst software components and the usefulness of such static analysis tools are presented in [11]. In this context, imagine an engineer, trying to understand some segment of code. For example the engineer may need to examine how a function is implemented or how an instance of abstract data type is composed in the program language specification. Engineers have to contend with the limited support available in some text editors using primitive key board manipulation. In Disha we translate source code into HTML pages such that users can navigate from one location where a variable is used to a location where it is defined and from the point of variable definition to a point where the type declaration is specified. These may be located across files and HTTP/HTML protocol in combination afford an acceptable level of transparency. It should be noted that there are severaal other language specific translation utilities [12] on the internet and Disha is one other translation utility. Disha differs in that Disha includes other services seamlessly integrated with the translator utility.
The Architecture
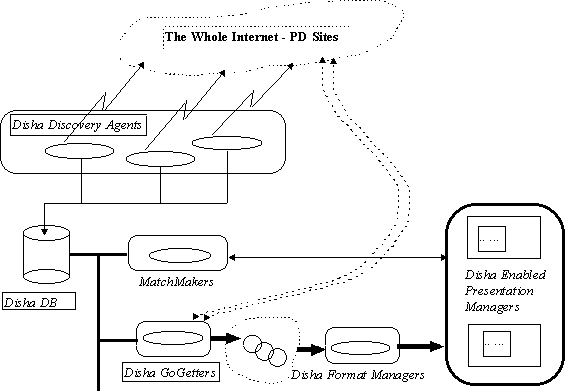
Disha is an instance of the IDAM architecture [7] and is comprised
of several independent agents each specializing in a specific
aspect of the problem at hand as shown in the diagram here.
The Disha system builds a catalog of software components in public domain packages. As software engineers work with source files, the Disha matchmaker agents, asynchronously, search for matching catalog entries whenever the engineer enters a symbol external to the language system. In other words ketwords within a language are ignored. If appropriate catalog entries are found, the Disha GoGetters fetch the package from the location indicated in the Disha DB while the Disha MatchMakers present visual cues for each of the catalog entries found on the engineers desktop. If the engineer should pursue a Disha cue, the corresponding packages are first unpacked then translated into html documents. The engineer is then transported to the html document.
Discovery Agents
These agents visit various sites and examine available artifacts, extract meta-information and catalog them. To begin with location, package information, language, abstractions and meta information such as timestamp and size are cataloged.
Disha DB
This is a database where in the information is stored. The database clients are insulated from the particular database via a canonical database access library.
MatchMakers
These agents look for an opportunity to offer a cue to the user. Users may initiate/activate them. With minimal information these will identify pertinent Disha DB entries and pass that information to the GoGetters. For each matching catalog item a visual cue in the form of an icon is presented to the user. As time goes by these icons fade out. No more than 7 cues are maintained at any given time.
GoGetters
GoGetters armed with the meta information on plausible software artifacts of interest fetch them using anonymous ftp and or emailftp. Then the GoGetters disect the downloaded packages and pass them as a collection of source files to FormatManagers.
FormatManagers
These agents will render the mined software components in a format that meets the engineer's needs. Primarily, these agents render them in HTML and set up links to related (dependencies) artifacts.
PresentationManagers
Curretly we use commonly available web browser. Our long term goal is to migrate to collaboration aware browser that is capable of supporting synchronous browsing with Disha enabled applets.
Summary
In this article we have presented the rationale for just in time reuse and maintenance using web technologies. We have presented the rationale and the architecture for Disha, an environment which encourages just-in-time reuse and static analysis of software components using WWW technologies. In essence we believe that hypermedia and internet technologies, in particular, will radically change the way we practice software having an impact on every aspect of software life cycle. Disha is a small step in that direction.
Reference
[1] "Internet Engineering: Technologies, Protocols and Applications", Daniel Minoli, McGraw Hill, 1997.
[2] "Grep and Indexed Search", Gais Team, Internet ReSearch Laboratory, Department of CSIE, National Chung Cheng University, Taiwan. http://gais.cs.ccu.edu.tw/IndexQuery.html
[3] "Glimpse: A tool to search entire file systems", Glimpse Working Group, University of Arizona, http://glimpse.cs.arizona.edu:1994/
[4] "Practical Extraction and Report Language", The Perl Language Home Page. http://www.perl.com/perl
[5] "The Java Language: An Overview", http://www.javasoft.com/doc/Overviews/java/java-overview-1.html.
[6] "Tool Command Language/tcl", http://www.sunlabs.com/research/tcl.
[7] "Semantic Web for Collaborative Software Processes", Raman Kannan, http://www.monmouth.edu/monmouth/academic/dna/weti96ff.htm.
[8] I-DAM: An Active Digital Archive Management, Raman Kannan, http://www.monmouth.edu/monmouth/academic/dna/w3cf.html
[9] K.G. Pankaj and W. Scacchi, "On designing hypertext systems for information management in software engineering", Hypertext 87 Papers, November 1987.
[10] Sandra Heiler, "Semantic Interoperability", Research Directions in Software Engineering, ACM Computing Surveys, June 1995, 271-273.
[11] Yih-Farn Chen, "Reverse Engineering" in Practical Reusable Software. Editors Balachander Krishnamurthy, Wiley and Sons.
[12] A complete list of translators could be found either at
http:// www.w3.or g/pub/WWW/Tools/Filters.html or
http:// www.w3.org /pub/WWW/Tools/Prog_lang_filters.html