Scalable Architecture for Reliable, High Volume Data Feed Handlers
Raman Kannan
DNA Laboratory
Monmouth University
West Long Branch, NJ 07764
kannan@monmouth.edu
In the financial markets, perhaps it is appropriate to say that the "haves" are those who have the capability to process information at the earliest opportunity and the "have-nots" are those who pale in comparison. Today this capability is a direct measure of the robustness of the underlying information technology infrastructures and how well they are leveraged more than ever. In this context information processing includes both:
Of these --data communication and exchange-- is the domain of interest in this chapter. The monetary consequence associated with gathering, distributing and processing data in the financial domain is a question of survivability and profitability not a mere one-time economic reward. The ability: (1) to gather and deliver new kinds of data; (2) to leverage new networking technologies as they become available; and (3) to process them over diverse platforms around the world is an essential ingredient for competitive advantage in this domain. In this chapter we will present our experience in designing and deploying high availability infrastructures for "market data communication and exchange" under quite different operating environments. In the remainder of this chapter we shall refer to these infrastructures as "data feed handlers" (DFH).
In this chapter we focus on application partitioning, architectural design and customizable object oriented software artifacts -- such as frameworks, patterns, components and classes inclusive -- and benefits there of. Although important we do not elaborate on other essentials of successful software projects such as "requirements gathering", "joint application design", "configuration management" and several other best software engineering practices. The remainder of the chapter is organized as follows: In section 2 we present an overview of DFH using three different business scenarios; In section 3 a reference (generic) architecture for handling continuous data feed is presented; and in section 4 we present their systematic adaptation to meet the requirements by example. In sections 3 and 4 we will identify the role and illustrate the benefits of object orientation in building customizable, scalable architectures. In section 5 we will present a review of similar efforts in this area.
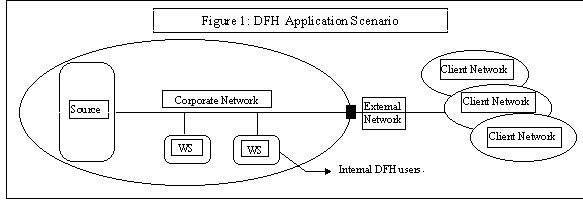
Data feeds in general are continuous and are valid only for certain duration, a weak form of soft deadline. Examples include sports update, weather updates, inventory depletion feed to suppliers and in the financial domain "market information feeds". Data feed handlers manage data feeds and as shown in Figure 1 there is a business need for the producers to disseminate the information to one or more consumers.
In this scenario, "data feed management" or the responsibility of a DFH includes:
There is no restriction on the location of the producers or the consumers, number of producers or the consumers, operating environment, and the business protocol between the producer and consumer. The DFH system must necessarily be independent and external to both the producers and consumers and must be able to work under diverse conditions. In subsequent sections we will engineer a generic architecture for DFH and evolve it for three particular scenarios.
DFH are required to run uninterrupted for any given length of time and distribute presented information near instantaneously. We carefully avoid the use of the term realtime because in our application scenario we do not have any (soft or hard) time constraints except: (1) that data be disseminated as soon as it is made available to the DFH system; and (2) when a deadline is missed or data items are not delivered that the producer and the consumer of the information synchronize using an agreed upon "recovery" protocol without requiring human intervention. Our data feed service can then be characterized as "best effort service". Market information feeds may include expert commentary, summary on what happened in the market and price feed --price feed being the most familiar--. One exception to our disclaimer that data feeds are not realtime is a steady flow of trades. Trades are the revenue generating business transactions, in the simplest case an agreement between a trader and a consumer to buy or sell securities. In the case of trade feed, missing a trade would be considered a hard system failure and undue delay would be considered soft system failure, because missed trades mean lost revenue, not to mention irate customers. Delayed trade would mean inaccurate risk/exposure analysis and would also be considered a failure. For example, an organization might decide never to speculate on interest rate fluctuation for over 25 million dollars. Given that if a trade speculating 15 million on interest rate fluctuation were not to be distributed instantaneously other unsuspecting (so they could claim) traders might exceed the daily limit by further speculating in the same market. When trades are involved expediency is the essence.
Figure 2: Data Feed Handler
In the most general sense data feeds may be characterized as a
publish/subscribe 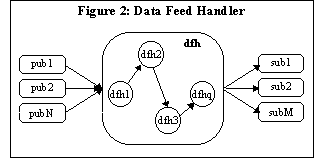 (consumer/producer)
problem. In this type of problem, some where in the network, a message
is produced by one or more producers. Also known as --logical data unit
(LDU)-- messages are the smallest unit of information that can be
exchanged. On the other end are one or more consumers who subscribe to
that information. The producer and/or the consumer may be a computing
element or a human being. Of the data feed management activities
enumerated in the previous section the central role of the data feed
handler is to accept messages as they are published and deliver all the
messages in the order they are published to all the subscribers, as
shown in Figure 2. In this simplified rendition messages
published by the set of producers [pub 1 through N] are processed by a
sequence of DFH resources ( q processing elements) as in a linear
bounded arrival processes [1B] and are finally delivered to the set of
subscribers [sub 1 through M].
(consumer/producer)
problem. In this type of problem, some where in the network, a message
is produced by one or more producers. Also known as --logical data unit
(LDU)-- messages are the smallest unit of information that can be
exchanged. On the other end are one or more consumers who subscribe to
that information. The producer and/or the consumer may be a computing
element or a human being. Of the data feed management activities
enumerated in the previous section the central role of the data feed
handler is to accept messages as they are published and deliver all the
messages in the order they are published to all the subscribers, as
shown in Figure 2. In this simplified rendition messages
published by the set of producers [pub 1 through N] are processed by a
sequence of DFH resources ( q processing elements) as in a linear
bounded arrival processes [1B] and are finally delivered to the set of
subscribers [sub 1 through M].
In summary, the specification for data feed handlers can be categorized into orthogonal profiles:
Now we illustrate the DFH problem using the three real world scenarios drawn from the financial domain.
Central to the price feed enterprise are business entities (security/brokerage firms) which are licensed to buy/sell securities and their representatives. We will refer to these representatives as traders and they quote a price to sell or buy instruments that they specialize in. Instruments here could be simple stocks of traded companies or other exotic securities such as options etc. In general this is a problem where there is one source and there are many subscribers on a given security or a class of securities managed by a trading firm. Usually, the datafeed subscribers are not the end customers but are the intermediaries who in turn transact with the end customer. The producer (publisher) and the subscriber may enter into a contract which specifies important trading parameters, such as volume, subscriber specific price markup, volume specific price markup/discount, time to live, data formats and recovery protocols.
Table 1: Publisher/Subscriber Transactions for Price Feed DFH.
Transaction Recipient is always the DFH except when stated.
Transaction Transaction Notes.
Originator
Publisher Start of Day Bursty message. 4000 or more
(SoD) Process messages in rapid succession.
Elapsed end to end time 2 to 6
minutes.
Publisher End of Start of Database is complete. Regular
Day process inter-day message will begin.
Publisher Price Update Fixed length.
Publisher Security Update New Security.
Publisher Status Update Trading halted/resumed.
Subscriber Start Is preemptive request in that it
Subscription may arrive while the DFH is
sending data. Overrides all
other pending requests from that
client. DFH must initialize a
snapshot of the current status.
Similar to Start of Day above.
Results in burst.
Subscriber Heart Beat Subscriber is alive.
Subscriber Retransmit Range Resend messages in range.
DFH 2 Subscriber Update messages <Same as above>
DFH 2 Subscriber Heart Beat DFH is alive.
DFH 2 Subscriber Start of Day Signals the beginning of
Message database refresh.
DFH 2 Subscriber End of Start of Same as above.
Day Message.
Figure 2A: Price Feed Handler
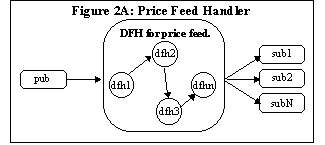 The
transactions between the publisher and consumer with the DFH are
presented in Table 1. In the particular system we implemented our
source was a single mainframe [Figure 2A, a slight variation of the
generic DFH]. Mainframe computers, while still are extremely reliable
high volume computing resources, they are not particularly suitable for
software development in the network era. Standard utilities software
developers come to expect are missing. Besides anything to do with
mainframes are prohibitively expensive. Thus, there was management
pressure to keep mainframe related activities to the minimum.
The
transactions between the publisher and consumer with the DFH are
presented in Table 1. In the particular system we implemented our
source was a single mainframe [Figure 2A, a slight variation of the
generic DFH]. Mainframe computers, while still are extremely reliable
high volume computing resources, they are not particularly suitable for
software development in the network era. Standard utilities software
developers come to expect are missing. Besides anything to do with
mainframes are prohibitively expensive. Thus, there was management
pressure to keep mainframe related activities to the minimum.
An important observation here is that the DFH processing is specific to each customer. Each customer may have their own set of requirements. For the system we deployed, one customer needed the "start of day" procedure and another customer did not. While these are profiles of the parties involved and the network, data transmitted can also be uniquely characterized. For example, new securities may be offered for trading and in some case trading on an existing security may be suddenly halted due to ultra heavy trading (supply and demand imbalance). These customers may be located anywhere where digital bits can reach (across building, town, country and the whole world) and these links are prone to failure. Consequently, recovery and replay protocols are very important. Recovery protocols are never the same and are particular to the business needs of the customer. Since some of these interconnections are patently unreliable (WAN networks) the two parties also agree to exchange so called "heart beat messages" at periodic intervals. Especially, to disambiguate any prolonged periods of inactivity from network failures. The price feed protocol includes an error recovery protocol by which the subscriber could request the publisher to retransmit a range of [dropped] messages from the past or a total refresh of the current offering at the beginning of a subscription session. In other words there may be different kinds of messages varying in semantics, content, structure and size. However, messages are self contained in that while a message may trigger the transmission of other messages they do not refer to other messages. The protocol is deliberately stateless as we will explain below. The data feed handler is the intermediary or the facilitator for all the above transactions. DFH must do so in a reliable manner and must be available at all times. Regardless of whether the producer is on-line or not. Regardless of whether the consumers are on-line or not. Subscribers may turn on and off their subscriptions any time as and when they need, in other words, subscribers may or not be in sync with the publishers. Publishers may publish data when there are no customers and customers may subscribe when there are no publishers. The protocol being stateless, synchronization is not a major issue. In the pricefeed system a log of every message transmitted to the client is maintained for reasons we will present later, in an appropriate context.
Note that in the price feed data feed, the subscribers and the publishers always exchange a single message at a time. The LDU between any two parties are the same. This need not always be true. As a matter of fact in Section 2.2 we describe a scenario where a single LDU injected into the DFH can explode into multiple LDU.
Consider the commentary from a proprietary vendor and summary of portfolio available on the internet based services as shown here.

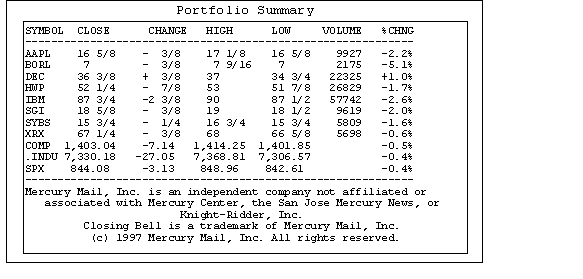
Summary
Each of these in its entirety is a LDU and are called "pages". In other words "pages" may be submitted to the DFH and must be distributed as efficiently and as reliably as possible. However, in some interesting cases "portions of a page" or page fragments may as well be submitted. For example, consider a scenario, where the one of the stock prices (say Intel symbol INTC) begins to move rapidlyand the producer may wish to update the page on all the subscribers by offering visual cues (blink, highlight, blankout etc.) just for the concerned page segments. Our earlier definition of LDU has to be modified to include such fragments as well. Integrity of the data is of paramount importance here for obvious reasons. We cannot help but think about HTML and SGML which are page description languages but for various reasons (including compatibility, efficiency and business related) the above pages are described in an ASCII based proprietary description language (pdl). The particular pdl in use is of no consequence due to our design strategy as we will demonstrate in the following section.
Figure 2B: Page Distribution
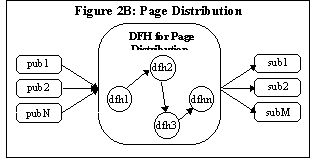 There are
numerous differences between the price feed scenario and the page
distribution scenario even at the business level. There may be more
than one contributor (commentators) as shown in Figure 2B. Pages have
immutable identifiers for their life time. For example, Reuters Page
924, may be designated for US Treasury Bond Options pricing. However,
content will change reflective of the prevailing market conditions.
Thus, as opposed to price feed, where each LDU is independent and self
contained, in a page distribution, LDU may be in the context of other
LDU. Here again consumers may turn on and off their subscriptions but
may request a refresh of previously unsubscribed pages when they resume
the subscription. Consumers may request one or more pages or all of
them to be refreshed. Thus, a page distribution system supports a
different interaction model than the pricefeed system. The volume also
varies. Updates and page contributions are not as frequent as in the
price feed system. On-demand instrumentation (monitoring and logging)
is required.
There are
numerous differences between the price feed scenario and the page
distribution scenario even at the business level. There may be more
than one contributor (commentators) as shown in Figure 2B. Pages have
immutable identifiers for their life time. For example, Reuters Page
924, may be designated for US Treasury Bond Options pricing. However,
content will change reflective of the prevailing market conditions.
Thus, as opposed to price feed, where each LDU is independent and self
contained, in a page distribution, LDU may be in the context of other
LDU. Here again consumers may turn on and off their subscriptions but
may request a refresh of previously unsubscribed pages when they resume
the subscription. Consumers may request one or more pages or all of
them to be refreshed. Thus, a page distribution system supports a
different interaction model than the pricefeed system. The volume also
varies. Updates and page contributions are not as frequent as in the
price feed system. On-demand instrumentation (monitoring and logging)
is required.
Table 2: Publisher/Subscriber Transactions for Page Distribution
DFH.
Transaction Recipient is always the DFH except when stated.
Transaction Transaction Notes.
Originator
Publisher Accept a page. A page has an immutable
reference id.
Previous version of the same
page is no longer valid. Forward
to all subscribers.
Publisher Accept a page Update the specified page and
fragment. forward to all subscribers.
Subscriber Start it may arrive while the DFH is
Subscription sending data. Overrides all
other pending requests from that
subscriber and must not affect
the input or other subscribers.
Subscriber Heart Beat Subscriber is alive.
Subscriber Refresh a page. Send the specified page.
DFH 2 Subscriber Send a page DFH does not send a page at a
fragment. time. The LDU between Subscriber
and DFH is a page fragment. Page
fragments are interleaved.
DFH 2 Subscriber Heart Beat DFH is alive.
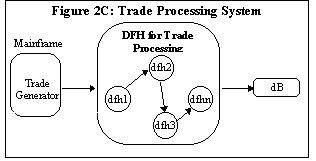 As a final
variation to the family of data feed systems, consider a trade logging
(processing) system we deployed by customizing (extreme at that) the
DFH infrastructure. Here a trade consists of several smaller
transactions -- or records-- . Each record represents a buy or a sell
[securities] or a delete (cancel) a record. A trade consists of zero or
more of these records. These trades were entered from various terminals
and were consolidated in a mainframe. But for various business reasons
the trades were required to be populated on yet another database. The
high level architecture for this system is shown in Figure 2C.
As a final
variation to the family of data feed systems, consider a trade logging
(processing) system we deployed by customizing (extreme at that) the
DFH infrastructure. Here a trade consists of several smaller
transactions -- or records-- . Each record represents a buy or a sell
[securities] or a delete (cancel) a record. A trade consists of zero or
more of these records. These trades were entered from various terminals
and were consolidated in a mainframe. But for various business reasons
the trades were required to be populated on yet another database. The
high level architecture for this system is shown in Figure 2C.
Note that we have one producer and one customer. However, due to the fact that the unit of information being exchanged here is a trade, several interesting requirements have to be taken into consideration. First and foremost trades are to be processed atomically. In other words, all though a trade is composed of several records (representing individual buy and sell records), either all of them have to committed to the database or none of them as in any other transaction processing system. Hence, the temptation to open a transaction on the database is understandable but it is not viable because: (1) these trades are long duration transactions. In other words a trade could remain open for hours if need be as the trader and the customer negotiate all the details of the components; (2) Moreover, there may be a number of trades open at the same time; and (3) to top it all a trade may never be completed. Although, all most all commercial databases support the notion of transactions with what is known as ACID properties with specific performance guarantees, such guarantees are valid only for short lived transactions. Thus, using the features of a readily available database was considered but did not meet the above requirements. Consequently, we customized our DFH framework to implement a "lazy" transaction processing system with full recoverability in that transactions are not committed to the database until they are closed. In other words, each transaction has three states; open, closed and database-committed. As records are submitted they are initially transformed and stored in a persistent store. Only when the trade is closed in reality, it is then a database transaction is opened, all the constituent records are posted to the database and the database transaction is closed. In other words, the database operations are performed at the very last moment, hence our characterization "lazy" transaction processing. As an additional quirk, to be in sync with the source (trades or records cannot be lost or dropped) an acknowledgment protocol was required between the source and DFH.
Table 3: Provider/Consumer Transactions for Trade Processing DFH.
Transaction Recipient is always the DFH except when stated.
Transaction Transaction Notes.
Originator
Provider Start trade feed. Expects a sequence number of the
next trade expected by the DFH.
Once in the morning DFH sends
000 to start the trade
processing system.
Provider Begin a trade. A new trade.
Provider Accept a trade DFH is to post this record into
record within a the appropriate trade container.
trade.
Provider End a trade. Close an existing trade and
commit it to the DB.
Consumer (DB) NONE Except for return (status)
values of attempted returns,
commercial DB do not initiate a
dialog with DFH. Transactions
are pushed by the DFH onto the
DB.
DFH 2 Consumer Open Transaction. Atomic, Consistent, Isolated and
(DB) Durable with (ACID) properties.
DFH 2 Consumer Post a record. Insert/Delete/Modify a DB
(DB) record. SQL/DML.
DFH 2 Consumer Close Transaction Commit the transaction.
(DB) Note that abort transaction is
not a DFH primitive because of
lazy evaluation.
In closing, we have introduced the notion of data feeds, general purpose data feed handlers that manage such data feed and three different business scenarios where such data feed handlers are applicable. Now with this background we introduce a generic (reference) component based architecture for any DFH and then evolve the particular architecture for the three DFH application scenario presented: (1) a price feed; (2) a page distribution system; and (3) a trade processing system.
DFH we present here is a component based architecture leveraging several different object oriented concepts. There is much debate over the terms including object orientation, architecture, framework, components, patterns, classes etc. We use these terms with a specific intent. For a brief introduction please refer to the primer on "Objective Taxonomy" in Appendix 1.
Optimal benefits of building a distributed application such as concurrency, fault tolerance, isolation and reliability can be realized if only if the distributed applications are designed using good principles such as:
Division of labor also known as, application partitioning, is arguably the most important.
Application partitioning is a design activity, in particular, one of devising a functional architecture. Partitioning is a wicked science in that there is no formula or rule for decomposing a given problem into the best partitioned architecture. Except that there are guidelines regarding application partitioning: (1) functional units (classes, patterns, components and frameworks) must be cohesive. Such components which fulfill a single minded objective of the application allow us to refine those distinct functions independently; And, (2) inter-component communication must be kept to a minimum so that the communication overhead is lowered. However, we should note that DFH is necessarily communication intensive.
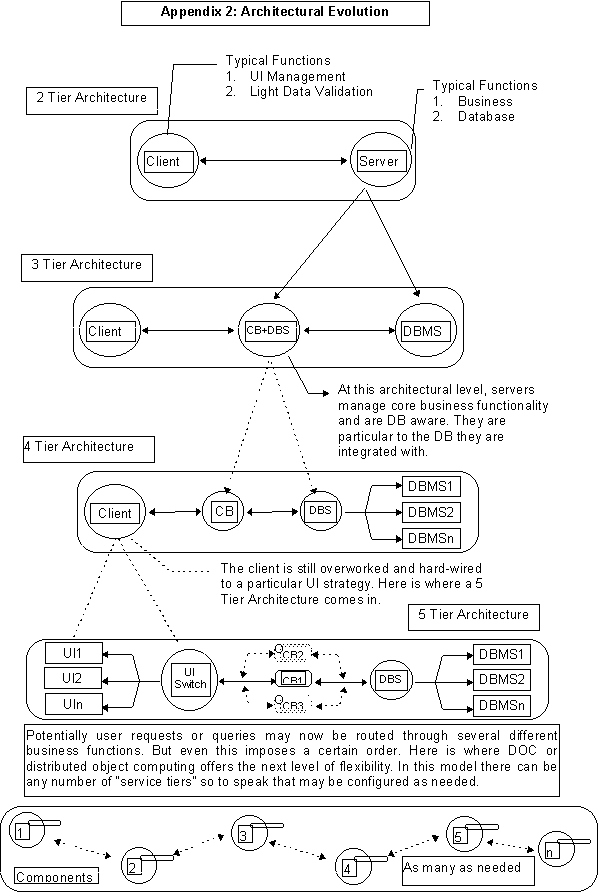
Software architecture defines and lays the foundation for many desirable properties of software systems. There are cookbook models of application partitioning [16] and for a basic introduction refer to the primer on "Architectural Evolution" in Appendix 2. Our system is centered around distributed components and our primary motivation for adopting distributed object/component computing and we quote [17] "is to simplify the development of flexible and extensible software." Division of labor with well defined separation of concerns is a direct consequence of this strategy.
We divide the DFH problem into a collection of cohesive, dependent but autonomous components:

These components are cohesive in that each component is dedicated to a particular aspect of the feed handler. Dependent in that each component depends on other components for the data. Autonomous in that each component can execute and continue to be well behaved even in the absence of other components. With partition we achieve very high degree of fault isolation and containment. For example, if the end client were to fail only the FDA are affected. If the SLR is corrupted, the subscription list, data store and all else remain functional until the SLR is resumed. SLR is a component which reads from a network device external to the DFH framework and writes it to an internal network device managed by another DFH component. This scheme is to insulate the DFH from the data parcel, flow control, connection and communication issues that may be peculiar to the external sources. We separate CQM (managing client requests) and FSS (populating the store) so that FSS is completely isolated and independent of client interactions. CQM are transient components (short lived unix processes) in that they are created as needed. But the FSS is always active. FIS are also components which provide unobtrusive instrumentation. FIS components attach to shared memory segments and read messages as they are processed. They are unobtrusive in that they are read only clients and the shared memory servers do not observe any mutual exclusion strategy. The reference architecture is shown in Figure 3:
Architectures facilitate structural stability at the level of abstraction they are devised and it is object orientation that facilitates evolvability shielding the architecture from instability at lower levels of abstraction. Fabricating a DFH solution to a particular problem is reduced to a problem of selecting the appropriate components, interconnecting and specializing them as needed. Architectures aid in selecting the components and interconnections. Object oriented techniques facilitate our ability to specialize without disrupting the stability afforded by the architecture.
We now demonstrate that the three business scenarios we presented can be (and most other business objectives in the domain of data feed services) achieved by a combination of at least one SLR, as many DFH core components as needed and one FDA. In this section we present the adaptation of the reference DFH architecture to the three particular problems we introduced in Section 2 and the effectiveness of the OO techniques we have used.
The particular architecture for the price feed handler consists of several cooperative servers as shown in Figure 4. The Feed Data Server (FDS) (an instance of SLR) maintains a communication channel with the source and the data is passed as is to the Subscription Manager (SM). The SM forwards the messages to the Feed Delivery Agents (FDA). The role of FDS is to receive data as fast as the source can deliver and buffer the feed as necessary when the SM is busy forwarding. The separation between the receiver and the forwarder is necessary to avoid holding up the source. The FDAs are agents that customize the feed data according to particular customer requirements. The Feed Store Server (FSS) is a special FDA which stores the entire feed in a persistent store so that all the messages can be replayed in the order they were generated at the source. The Replay Agent (RA) is a liaison between the FSS and the numerous FDAs. The RAs are transitory agents which request a feed replay from the FSS and feed it to the FDAs. The RAs are transitory in that they are created by the RA Dispatch Executive, RAX, whenever a FDA requests a replay and exit when the feed is completely played out. While FSS is dedicated to storing the feed data, the RAs manage replay requests from any one of the FDAs representing a customer. The separation between RA and FSS is also essential so that replaying the messages to a particular customer does not affect the price feed or storing the feed into the database. Thus, FSS is isolated from communication errors and delays during replay. RAX is a dispatcher to provide concurrent RA service and creates one RA per replay request from the FDA. Notice that several FDAs can be activated (initiated) simultaneously and more importantly exposure to failures with a customer is limited to the FDA servicing that customer.
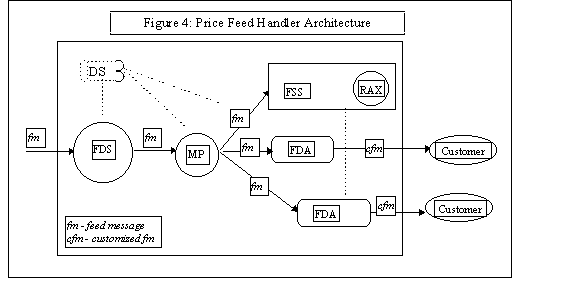
DS is a simple light weight directory service component provides higher degree of transparency and migratory capabilities for the components. For a discussion of the capabilities of the DS see [19]. DS is not integrated yet.
Subscription Managers (SM) and the Feed Delivery Agents (FDA) together implement feed delivery framework and the interaction between them is realized using Publisher/Subscriber patterns. We present these patterns in a subsequent section. The price handler system has been in production on a variety of platforms for well over three years. During the "Start of Day" phase a feed burst of upto 7000 messages is handled within a duration of 3 to 6 minutes over geographic distances. On any given trading day this system transfers on an average 60000 messages.
The Page Distribution system is fundamentally different system and is work in progress. The unit information, a page, is fundamentally different from a price quote. Price quotes are transient while pages are long lived and are distinct. Content of the page may vary. Thus, in addition to the distribution, storing and retrieving the pages are additional functional requirements of the problem. Furthermore, since we now have more than one source, transferring the pages to the Page Distribution System is another essential requirement. We first decompose the Page Distribution System into three major subsystems as shown in Figure 5.
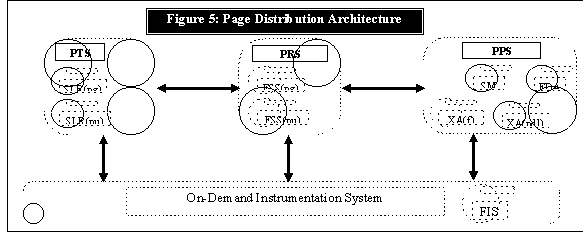
The Page Transfer Subsystem (PTS) is a customization of the SLR component to receive two different kinds of input streams. One is a stream of pages and the other is an update to an existing page. A page is a represented as a file. The SLR(pg) components receives pages and stores them in the Page Repository Subsystem (PRS) using a Page Replacement Component (FSS(pg)). When a page update is received the corresponding page is updated in the Page Repository using Page Update Component (FSS(pu)). Page Repository is a customized Feed Store System. The architectural mismatch between the Page Repository and a record oriented Feed Store are not trivial and at this time a final(stable) solution is not in place. The Page Publisher Subsystem (PPS) is however a direct descendant of the Publisher Subsystem of the reference architecture. Here the SM component does not know anything about the internal structure of the data units being exchanged. So we introduce a transaction agent (XA) to fragment pages and pass the fragments to the SM. The pages are submitted in a proprietary page description language (pdl). Since customers may require these pages to be delivered in other page description language we have an additional translation agent (XA (pdl)).
Lazy Transaction Processing (LTP) receives trades which consists of one or more records. Each record represents a buy/sell of securities or cancellation of a previous record. Trades can be open, active and closed. When a trade is closed the trade is to be committed to an external database that supports ACID transaction semantics. The LTP configuration is different in that there is exactly one source and one client (external database). However, the reference model is consistent with this scaled down version as well. The difference is in data processing methods. We now have to preserve the state(s) of many trades that are exchanged between the source and client. Furthermore, a trade or a record cannot be dropped even if the source or the client drops. In the event one of the system does abort, LTP must recover from where it failed. Thus we partition the problem into three components:
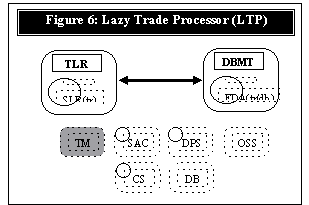 In Figure 6 we
present the LTP architecture comprised of two subsystems: (1) TLR,
which is a customized SLR(tr) with trade processing abilities; and (2)
DBMT, a database manager for trades. The communication aspects of both
TLR and DBMT are rather straight forward. The opportunity here is that
both TLR and DBMT have to be "transaction" aware but have to
process them differently. The TLR receives trade records and posts it
to the persistent store. Whereas the DBMT posts the trade to the
database. Thus we implemented a Transaction Management Framework (TM)
in which some essential implementation details were left unspecified.
By definition frameworks are incomplete specifications to a specific
problem which may be customized. Now we present the Transaction
Management Framework and the details of customization.
In Figure 6 we
present the LTP architecture comprised of two subsystems: (1) TLR,
which is a customized SLR(tr) with trade processing abilities; and (2)
DBMT, a database manager for trades. The communication aspects of both
TLR and DBMT are rather straight forward. The opportunity here is that
both TLR and DBMT have to be "transaction" aware but have to
process them differently. The TLR receives trade records and posts it
to the persistent store. Whereas the DBMT posts the trade to the
database. Thus we implemented a Transaction Management Framework (TM)
in which some essential implementation details were left unspecified.
By definition frameworks are incomplete specifications to a specific
problem which may be customized. Now we present the Transaction
Management Framework and the details of customization.
The beauty of frameworks is that they provide a convenient way of codifying the commonality within a family of problems and yet allow for the independent customization for each problem within that family so that the entire family of problems can be solved elegantly and economically without any compromise. The commonality between TLR and DBMT is that both subsystems have to detect when a trade is opened, closed and have to process records as they are received. The difference between them is that TLR stores the records in a persistent store whereas the DBMT commits the transaction to an external database. The framework consists of three classes: a transaction manager, transaction and records that make up a transaction. We wish to use these classes under different conditions.
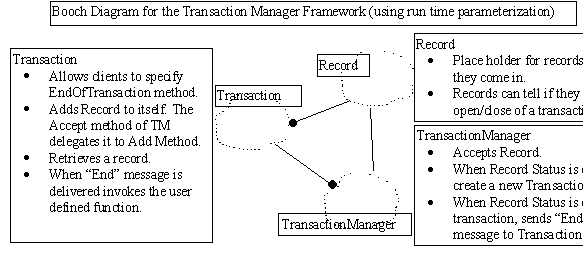
DBMT differs from TLR in two ways: (1) Initialization and Termination
(to setup and dismantle database connectivity); and (2) what happens
when a end_of_transaction is sensed (commit the records to a commercial
database as opposed to committing the records to a persistent file
store). It is under such conceptually similar but operationally
different scenario that frameworks are relevant. Because the frameworks
can be used to codify the conceptual similarity deferring the
customization to a later phase. In the following source listing we
present relevant portions of the Transaction Manager Framework. 
Clients of transaction manager can customize the trade processing but retain the transaction semantics. Note that runtime TransactionManager objects are instantiated with application specific customization functions.
Partitioning an application enables us to analyze components within a limited context. Isolated from other responsibilities of the entire application, it is easier to identify patterns that are candidate solution to the particular problem being addressed by specific components. As the DFH evolved over these years we discovered the applicability of numerous patterns. We present a selection of these patterns: (1) Publisher/Subscriber (Observer) pattern; (2) Header (Bridge) pattern; and (3) ParcelService (Facade) pattern.
Pattern Name: Subscriber/Publisher
Intent
Allow a continuous data generator to accept subscription request, manage subscription list and maintain the data feed to any number of consumer in a distributed environment with very little exposure to substrate system primitives and very high genericity/reusability.
Also Known As
Subscriber is a specialization of the Observer Pattern[6] of the MVC framework to maintain continuous data feed.

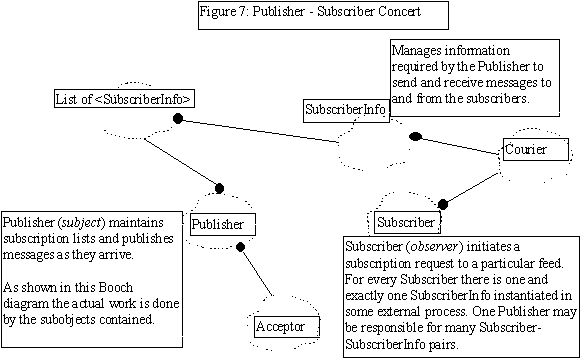
Applicability
The Publisher/Subscriber Pattern can be used to:
The Publisher-Subscriber implemented here is a domain specific customization of the Observer pattern. These are composite objects which are made up of IPC wrappers and various foundation classes, such as the Acceptor, Connector, Courier and MultiPlexor wrappers discussed in [18][20]. Acceptor is the communication engine for the Publisher objects to accept incoming subscription requests. The Connector is the communication engine for the Subscribers to initiate a subscribe request with the Publisher. Courier is a transport object. The MultiPlexor is a wrapper to maintain multiple subscription streams.
Participants
- Accepts Subscribe/Unsubscribe Requests
- Enforces distribution criteria
- Publishes message units
- Subscribes to data sources
- Retrieves Messages as they arrive
- Maintains a Courier Object for communication
- Maintains a list of SubscriberInfo
- Publishes the message to all the subscribers maintained by the ListManager
Collaborations
Consequences
Implementation
1. Maintaining Subscriber List
IPC Wrappers, such as, Courier, Connector and Acceptor are used to maintain references, make a connection and accept an incoming subscription requests, respectively. These are network distributed references. Robustness and richness of the communication capabilities are delegated to these wrappers.
2. Message Independence
The framework presented here is oblivious to the kind of message being exchanged. Messages are treated as a stream of bytes of definite length. The framework is not responsible for data representation issues. The framework cohesively addresses the problem of publishing messages as they arrive.
3. Recovering from Communication Errors
Distributor encapsulates all tasks relating to detection and recovery from underlying communication failures. Distributor is used to multicast the message and provide fault tolerance.
4. Maintaining Priority Subscribers
The ListManager maintains various lists of equivalent subscription priorities and enforces the distribution policies.
5. Who initiates message exchange?
In our framework messages are generated by an external source and is delivered to the Publisher which then distributes to the set of current subscribers. The subscribers customize and deliver to the end client. Thus, the whole process is driven by the source.
6. Resolving Subscriber Location
The Connector and Acceptor Wrappers provide these resolution services. Publishers and Subscribers are not concerned about these aspects.
Known Uses
The Publisher/Subscription framework can be used to maintain multiple streams. With modifications the service may be extended to multimedia services as well.
Pattern Name: ParcelService
Intent
Exchanging application objects between two processes involves packing and unpacking these objects appropriately and managing the communication issues. Clients have to contend with the two different abstractions (1) "packaging abstraction" and (2) the "ipc abstraction". The packaging information includes both header information and content of the package.
Also Known As
Facade from [6] "provides a unified interface to a set of interfaces in a subsystem. Facade defines a higher-level interface that makes the subsystem simpler to use.



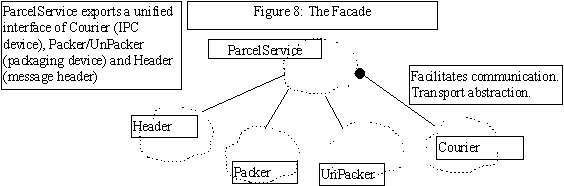
Applicability
The ParcelService Pattern can be used to:
The ParcelService implemented here is a direct application of the Facade pattern [6].
Participants
- Uses Packer/UnPacker and Header Classes. Contains a Courier.
- Delegates the work appropriately.
- Facilitates communication over a connection.
- Packs/Unpacks application objects onto communication buffer.
- isolates information about messages headers.
Collaborations
Consequences
Implementation
1. Information Exchange
IPC Wrappers, such as, Courier, is used to communicate. Robustness and richness of the communication capabilities are delegated to these wrappers.
2. Header Management
The Header (a Bridge pattern itself) is used to manage header specific information.
3. Packing and Unpacking application objects
Packer and UnPacker are used to pack and unpack application objects.
Known Uses
The ParcelService (facade) can be used to provide a unified interface to complex subsystem.
Pattern Name: Header
Intent
Allow clients to exchange information with other processes transparent to the actual message header protocol used.


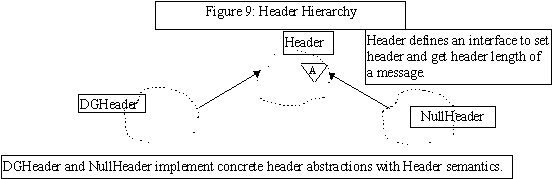
Also Known As
Header is an example of the Bridge Pattern[6].

Applicability
The Header Pattern can be used to:
The Header pattern implementation is a direct application of the Bridge pattern [6].
Participants
- Defines abstract interface to header objects.
- Message protocols which do not involve any header information at all.
- Header specific to a particular configuration.
Collaborations
Consequences
Implementation
1. Atomic Messages
If Headers are considered separate from Body of message, then atomic transfer of whole message may be expensive.
Known Uses
The Header hierarchy can be used to hide details of header implementation.
One of the prominent patterns employed in DFH is the Publisher/Subscriber pattern. The Publisher/Subscriber pattern is a well known pattern and is derived from the Observer pattern [6]. The relevance of the Observer pattern to our discussion here is that an Observer pattern is defined to be " .. used to decouple objects so that changes to one can affect any number of clients without requiring the changed object to know the details of the others" [6]. And in the DFH application scenario the stream of messages generated by a source represents the "model" and the customized stream of messages generated by the subscribing agents represent the "views". The role of the distributor/publisher agent is to notify the list of subscribing agents when a new message arrives. Subscribers are observers.
The Publisher/Subscriber pattern has been used in numerous other implementations. In [7] the Subscriber-Publisher pattern is used to implement the CORBA Event Service Specification within the CORBA Object Service Specifications. Rogers [7] presents two concrete examples of Observer pattern: (1) CORBA Event Notification Services; and (2) Security Alarm Reporting. Publisher/Subscriber is also discussed in [4][13] in this context. In [14] example scenarios of the Subscriber/Publisher pattern is presented and a formal contract is specified. The earliest use of Subscriber-Publisher pattern is perhaps within the Smalltalk fame Model-View-Controller (MVC) framework [15]. The MVC is a rather complex design construct and is usually made up of several simple and cohesive design patterns and one of them is the observer pattern.
Understanding the customer requirements and defining a conforming architecture are the very foundation of a successful software project. Real world systems have real requirements and are naturally complex. Understanding the requirements and the business context is the first and foremost step toward automation. Unfortunately it is neither inexpensive nor easy to come. Time consuming but quite rewarding over unusually long period of time. There is no such thing as too much detail.
Next important endeavor toward a successful software project is the software architecture. We quote Barry Boehm [21] here "If a project has not achieved a system architecture, including its rationale, the project should not proceed to full-scale system development. Specifying the architecture as a deliverable enables its use throughout the development and maintenance phase."
From a system perspective the DFH framework we have implemented is comprised of an architectural framework and a realization framework. The architectural framework (DFH/AF) is independent of the realization framework (DFH/RF). DFH/AF merely stipulates how the components may be configured. This guarantees stability (availability) and scalability. We presented a reference architecture for data feed handlers. Then we customized the reference architecture by (1) adding or removing problem specific components; (2) by reconfiguring the interconnections between the components; and (3) by introducing new components as needed.
The DFH/RF is a collection of classes (C++) which can be easily substituted with equivalent classes and they provide the services to realize the capabilities of the components. We demonstrated the utility of object oriented artifacts in the form of patterns and class categories. We presented the details of Publisher/Subscriber (Observer) pattern, ParcelService (Facade) pattern, and Header (Bridge) pattern. We also demonstrated the utility of components (SLR, FIS, etc.) and frameworks with the customizable Transaction Manager framework.
From a domain perspective the DFH is a collection of components (executable applications) that can collectively receive high volumes of arbitrary market data, maintain a history database and disseminate the data as they are received to one or more customers. The DFH/AF explicitly addresses concerns regarding customization:
without affecting other customers who may also be receiving data at the same time.
The DFH has been used to exchange US Treasury Bond data, Pages, and Transactions over WAN/LAN involving commercial databases and other middleware toolkits. Our experience is that understanding the domain and the architecture are the most important aspects. Without the architectural stability and the evolvability due to object orientation the level of customization we have achieved would not have been possible. Without understanding the domain we could not have possibly satisfied customer requirements in such varied environments. The DFH system has evolved over 4 years and the investment in the analysis and design phase has been truly rewarding.
This chapter is a report of an ongoing project at Asset Enterprise Technologies Corporation, New Jersey since 1994 in contract to major multinational financial powerhouses. DFH instances are use at these financial corporations. Without the time, support and sharp technical and business acumen of the following dedicated professionals none of this would have been possible: William Sweeney, Byron Nicas, Vadim Dosych, Mitch Haviv, Angelo Susi, Dan Marcellus, Nachum Greenspan, Robert Sachs, Virendra Agarwal, Joel Rosner, Peter Delucia, Karen Minasia, Flourian Miciu, Henry Ming, Paul Kennery, John Sabini, Marge Kaelis, Kris Stala, Kathy Delligatti, Joseph Costantini and the many contributors of ACE Mailing List which is a think-tank in this domain with instant answers to most questions. This work is not funded by federal, state or other public agencies. The author is grateful to his family, Concurrent Engineering Research Center, West Virginia University, Software Engineering Chair Professor Jorge Diaz, Director of Center for Technology Transfer and Development Dr. Larry Dworkin and many other colleagues at Monmouth University for their encouragement and support.
[1a] "Multimedia:Computing, Communications and Applications", Ralk Steinmetz and Klara Nahrstedt, Prentice Hall, 1995, Pages 228-229, ISBN 0-13-324435-0.
[1b] ib id, Pages 238-244.
[2] Efficient Consumer Response, Hemisphere, May 1997, United Airways In Flight Magazine.
[3] Booch, D. Object Oriented Analysis and Design with Applications. Second Edition. Benjamin/Cummings Publishing Company, Inc., Redwood City, CA 94065, 1994.
[4] "Pattern-Oriented Software Architecture: A System of Patterns", Frank Buschmann et. al., John Wiley, 1996, ISBN 0-471-95869-7.
[5] Advanced C++ Programming Styles and Idioms. Coplien, J. Addison Wesley Publishing Company, 1992.
[6] Gamma, E., R. Helm, R. Johnson, and J. Vlissides, Design Patterns: Elements of Reusable Object Oriented Software, Addison Wesley, Reading, MA, 1994.
[7] Framework-Based Software Development in C++, Gregory Rogers, Prentice Hall, 1997, ISBN 0-13-533365-2.
[8] Robert Orfali, et. al., "Client Server Components;CORBA meets OpenDoc", Object magazine, May 1995, pg. 55.
[9] Alan Brown and Kurt Wallnau, "Engineering of Component Based Systems" in Component Based Software Engineering, Selected Papers from the Software Engineering Institute, Edited by Alan Brown, pages 7-15, IEEE Computer Society Press, 1996, ISBN 0-8186-7718-X.
[10] Even Wallace, Paul Clements and Kurt Wallnau, "Discovering a System Modernization Decision Framework; A case study in Migrating to Distributed Object Technology" in Component Based Software Engineering, Selected Papers from the Software Engineering Institute, Edited by Alan Brown, pages 113-123, IEEE Computer Society Press, 1996, ISBN 0-8186-7718-X.
[11] "Software Architecture:Perspectives on an Emerging Discipline", Mary Shaw and David Garlan, Prentice Hall, 1996, ISBN 0-13-182957-2.
[12] David Garlan and Mary Shaw, "An Introduction to Software Architecture," in Advances in Software Engineering and Knowledge Engineering, Vol. I, World Scientific Publishing Company, 1993.
[13] P. Coad, "Object Oriented Patterns". Communications of the ACM, 33(9).
[14] "Design Patterns for Object-Oriented Software Development", Wolfgang Pree, Addison Wesley, ACM Press, 1995, ISBN 0-201-42294-8, pages 69-72 and 88-94.
[15] Glenn E. Krasner and Stephen T. Pope. A Cookbook for Using the Model View-Controller User Interface Paradigm in Smalltalk-80, Journal Of Object Oriented Programming, August-September 1988, 26-49.
[16] Alex Berson, "Client/Server Architecture", McGraw Hill, 1991.
[17] Steve Vinoski and Doug Schmidt, "Comparing alternative distributed programming Techniques", C++ Report May 1995
[18] Douglas C. Schmidt, ACE: The Adaptive Communications Environment, see http://siesta.cs.wustl.edu/~schmidt/ACE.html.
[19] Raman Kannan et. al., Support Environment for Network Computing, CERC-TR-RN-91-007, Concurrent Engineering Research Center, West Virginia University, Drawer 2000, Morgantown, WV 26505, May 1992. (internet: cerc.wvu.edu)
[20] Raman Kannan, Application Partitioning with Patterns, TR-MU-SE-DNA-95-002.
[21] Boehm, B. "Engineering Context (for Software Architecture)". Invited talk, first International Workshop on Architecture for Software Systems. Seattle, Washington, April 1995.
Classes, patterns, components, frameworks and architectures are all units of software artifacts (or tools) that help us manage complexity. In particular they all help us divide and conquer and achieve high degree of separation of concern. They vary in the degree of abstraction they afford. Subsystems and modules also deserve special mention. A module or a subsystem does not in itself violate any of the key characteristics of being object oriented. Given how the subsystem is constructed we can begin to characterize if they are object oriented or not. There is now some consensus on what constitutes being "object oriented" and for basic concepts please see [3].
"A class is an implementation of abstract data types" as defined by James Coplien [5].
A design pattern is and we quote from [6] "descriptions of communicating objects and classes that are customized to solve a general design problem in a particular context."
Components are interpreted and defined in many different ways. Components are sometimes referred to classes within a cohesive class library [7]. Others define a component as a unit of work and distribution [8]. We prefer components as a unit of work which are independent with a well defined context and interface and may even be executable as prescribed in [8][9].
Rogers[7] defines a framework as a partially completed software application that is intended to be customized to completion. "A framework is a class library that captures patterns of interaction between objects. A framework consists of a suite of concrete and abstract classes, explicitly designed to be used together. Applications are developed from a framework by competing the abstract classes". This definition of framework [a partial application that is completed by the developer or integrator] is also referred to as "application frameworks" [10]. As opposed to "integration frameworks" which refers to an infrastructure that is independent of application functionality [10]. Rogers differentiates a pattern from a framework in that patterns are prescriptions to a particular problem (need not include software) whereas frameworks are partial implementations to a problem. In other words frameworks are implementations in a particular language and may employ one or more patterns whereas patterns are problem specific but language independent prescriptions which may include illustrative implementations.
Objects, applications and systems are all realizations (instances) of these concepts. An object is an instance of a class. A well defined application is a realization of a framework. And if the applications are so devised that they execute independent and configured to work in concert with other applications, such applications are components.
Mary Shaw and David Garlan in [11] offer an abstraction of architecture to include "description of elements from which systems are built, interactions among those elements, patterns that guide their composition, and constraints on these patterns." In [12] offer a simpler definition that an architecture of a system defines the basic components of the system and their connections. Components here refer to units of functionality.