Internet: Can It Be a Federated Reuse Repository?
Raman Kannan
Bo Cao, Rajesh Rao, Joe Occoner and Zhen Chen
DNA Laboratory
Software Engineering Department
Bandish Chitre
Electrical Engineering Department
Monmouth University
West Long Branch, NJ 07733
Abstract
The evolution of internet has a mainstream communication medium has been super-accelerated with the advent of intuitive interface to the internet (WWW, email and other internet services). Vast amount of useful information assets are made available at ever increasing pace. But, what good is it if only we cannot use, all of it, at will, from anywhere, without having to go through a lot of technical wizardry if not painfully repetetive sequence of conversations with the system (mouse clicks, visiting pages etc...)? In essence: (1) there is a viable infrastructure; (2) vast amount of information assets; but (3) an acute lack of intuitive and effective access mechanisms. The existing access mechanisms do not scale with the size of the content. Our inability to exploit the internet resources has been the motivation behind our efforts in the IDAM project [1,2]. Our goal, in this project, is to integrate the various tools we have gathered (fabricated here or elsewhere) to render the whole internet as a federated reuse repository for software assets. In this article we present the concept, an architecture to realize the concept and the details of the subsystem components that make up the architecture. While we focus on the internet in this report our ideas, approach and software services can be readily used in IP enabled intranets.
Motivation
Software "Reuse" at best has been difficult. The problem has not been the lack of software assets or the willingness to share. The amount of code that is available in the public domain is beyond normal comprehension. But one of organization and ease of retrieval. Most of the effort in the reuse community has been to impose structure to the software asset repository by way of either a taxonomy, or retrieval mechanisms. Here in lies the fundamental difficulty. Software artifacts and engineers in particular do not and will not confirm to standards or structure in practice. A standard terminology does not exist and may never exist. Organizing software beyond normal configuration management in particular with reuse as an objective may not be efficient. Practitioners may not tolerate complex retrieval procedures.
Thus, we propose an alternate environment where: (1) practitioners do not wade through complex hierarchies of retrieval queries and software repositories. Instead reusable software artifacts must be delivered to the practitioner's desktop whenever an opportunity arises. In otherwords practioners do not retrieve software artifacts; and (2) most importantly, software assets need not be organized any more than for general purpose configuration management. There are no special software reuse repositories. Software assets exist --as is-- in the public domain and in corporate intranets. The system we propose will track, recall software artifacts as needed without any regard to where such artifacts actually reside. Practitioners do not have to construct structured queries but instead provide names of software components as they know it.
Use Case Scenario
Imagine a software developer with an immediate need to use the unix system primitive "setjmp()". While there are all the time honored methods of consulting a Unix Guru or the online manual, what if the software engineering environment offered an appropriate illustration dynamically extracted from the internet. In otherwords, the environment is capable of presenting a software segment using "setjmp()" to the developer, when necessary, and regardless of the location where the needed assets are located. In essence the environment we propose augments the user's ability to recall reusable software elements located somewhere in the internet. The system is situated and aware of the engineer's need.
Research Issues
There is no known solution or system that is capable of augmenting the developer as depicted above and a goal to fabricate such a system manifests itself into a variety of unresolved problems. For example, how will the system learn, track where the desired software components exist? How open should a search be? Entire internet? Or customizable by the developer to a select few preferred sites (gnu assets and wustl assets) or software vaults. When artifacts are discovered how will such information be stored and managed for efficient recall? Software assets are packaged using a variety of tools (tar, shar, source code, sometimes compressed and sometimes not). How can we unpack for examination and extract pertinent information conducive for software reuse? Finally, how do we present the information to the user? An engineer, once cued that software components involving "setjmp" exists, may now wish to see how it is actually used? Furthermore, may wish to what such components depends on before actually integrating that component into their solution. Given that a particular needed software component may actually be available in multiple locations how do we present the alternatives to the user (all of them or a subset of them)? How can we facilitate a focussed, cognitively-effortless (subconscious) "reuse" session?
An Approach
Disha
"Disha" in Sanskrit means direction. In a sense our objective is to provide direction to willing software engineers. Bhandish and Rajesh thought of Disha.
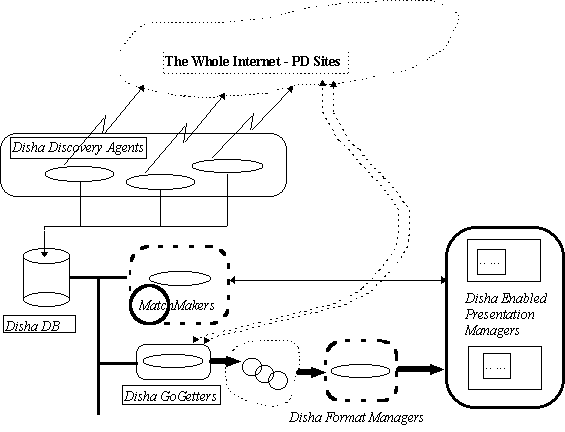
Discovery Agents
These agents visit various sites and examine available artifacts, extract meta-information and catalog them. To begin with Location, Packaging Information, Language, Abstractions. Bhandish and Raman have pondered about this. Bhandish has implemented some aspects of this.
Disha DB
This is a database where in the meta information will be stored. Not sure but this is least of the interesting pieces. Perhaps defining what is important (schema design) and what is not is interesting.
MatchMakers
These agents look for opportunity to offer a clue to the user. First cut, may be the user will initiate/activate them. With minimal information these will identify pertinent Disha DB entries and pass that information to the GoGetters.
GoGetters
GoGetters armed with the meta information on plausible software artifacts of interest will fetch them disect them and pass it on to FormatManagers.
FormatManagers
These agents will render the mined software components in a format that meets the engineer's needs. Will render them in HTML and set up links to related (dependencies) artifacts. Rajiv Rodriguez, Bo, Zhen are working on this for structured assests. Joe Occonner is also working on some aspects of this for unstructured assets ..
PresentationManagers
A Browser that is capable of supporting synchronous browsing with Disha enabled applets or other active components.